Feedback from participants and mentors#
This page shows the result of the mid and post-cohort feedback forms sent to participants and mentors
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def get_mcq_answer_counts(col, df):
'''
Get value counts for answers in multiple choice questions
:param col: column name
:param df: dataframe
'''
# split transform elements as lists
q = df[col].apply(lambda x: x.split(', '))
# get unique items & counts
return q.explode().value_counts()
def get_mcq_possible_answers_counts(col, df, answers):
'''
Get value counts for answers in multiple choice questions
:param col: column name
:param df: dataframe
:param answers: list of possible answers
'''
# split transform elements as lists
q = df[col].apply(lambda x: x.split(', '))
# get unique items & counts
value_counts = q.explode().value_counts()
# prepare possible answer counts
answer_counts = {c:0 for c in answers}
# parse answers to match to possible answers
other_answers = []
for a,v in value_counts.items():
if a in answer_counts:
answer_counts[a] = v
else:
other_answers.append(a)
answer_counts['Other'] += v
return answer_counts, other_answers
def get_question_possible_answers_counts(col, df, answers):
'''
Get value counts for answers in multiple choice questions
:param col: column name
:param df: dataframe
:param answers: list of possible answers
'''
# get unique items & counts
value_counts = df[col].explode().value_counts()
# prepare possible answer counts
answer_counts = {c:0 for c in answers}
# parse answers to match to possible answers
other_answers = []
for a,v in value_counts.items():
if a in answer_counts:
answer_counts[a] = v
else:
other_answers.append(a)
answer_counts['Other'] += v
return answer_counts, other_answers
colors = {
"participants": "#3182bd",
"participant_colormap": "winter",
"mentors": "#fd8d3c",
"mentor_colormap": "winter",
}
Mid-cohort#
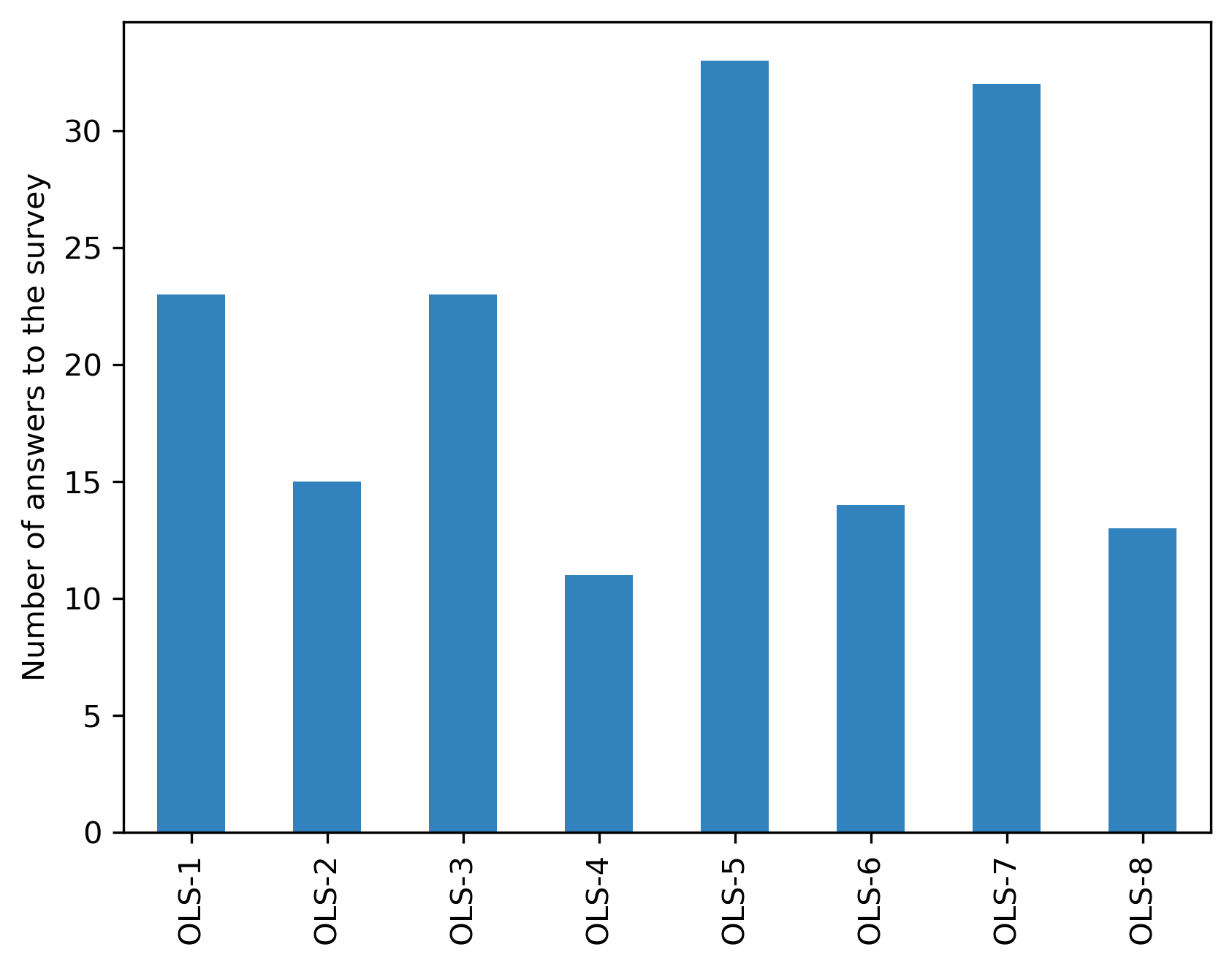
Participants#
url = "https://docs.google.com/spreadsheets/d/1-p1e2bXW7edR2o0vZ60pP2Su18wvRK9n4atoi-7wVYo/export?format=csv"
cohort_gid = {
"OLS-1": "814222007",
"OLS-2": "1061421385",
"OLS-3": "564694769",
"OLS-4": "797034637",
"OLS-5": "414286605",
"OLS-6": "0",
"OLS-7": "1676679295",
"OLS-8": "1949391298",
}
participant_mid_df = {}
answers = {}
for c in cohort_gid:
participant_mid_df[c] = (pd.read_csv(f"{url}&gid={cohort_gid[c]}")
.dropna(axis=1,how='all')
.fillna("")
.replace(c, "cohort", regex=True)
.replace("Information on before, during and after the call", "Information on before during and after the call", regex=True)
.replace(" on the google doc", "", regex=True)
.replace("I have attended 1-2 cohort calls, and watched the missed call on YouTube", "I have attended 1-2 cohort calls and watched the missed call on YouTube", regex=True)
.replace("I watched all the cohort calls on YouTube, but have not attended any call so far", "I watched all the cohort calls on YouTube but have not attended any call so far", regex=True)
)
answers[c] = participant_mid_df[c].shape[0]
answer_s = pd.Series(answers)
fig, ax = plt.subplots()
fig.set_dpi(300)
answer_s.plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Number of answers to the survey')
Text(0, 0.5, 'Number of answers to the survey')
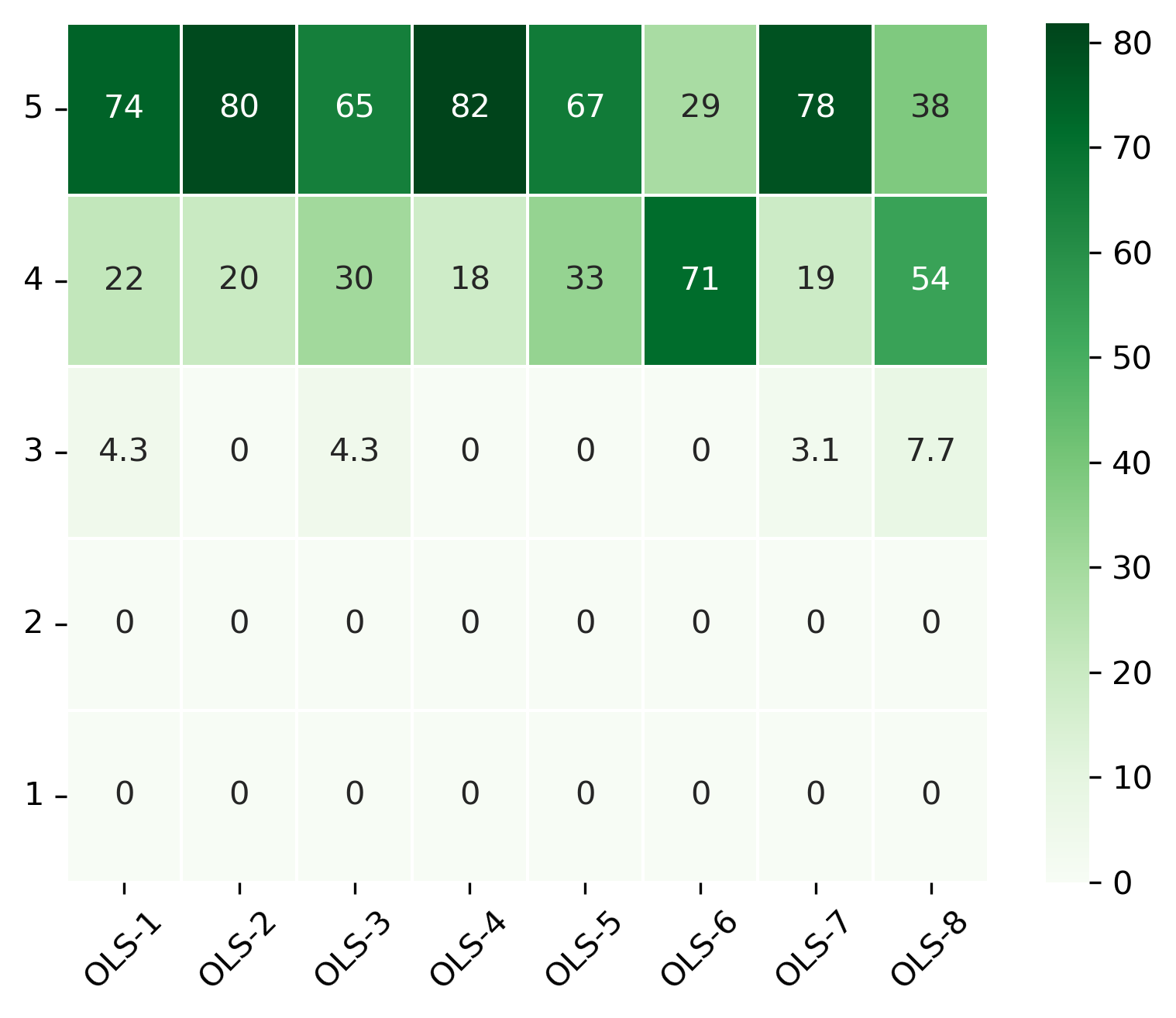
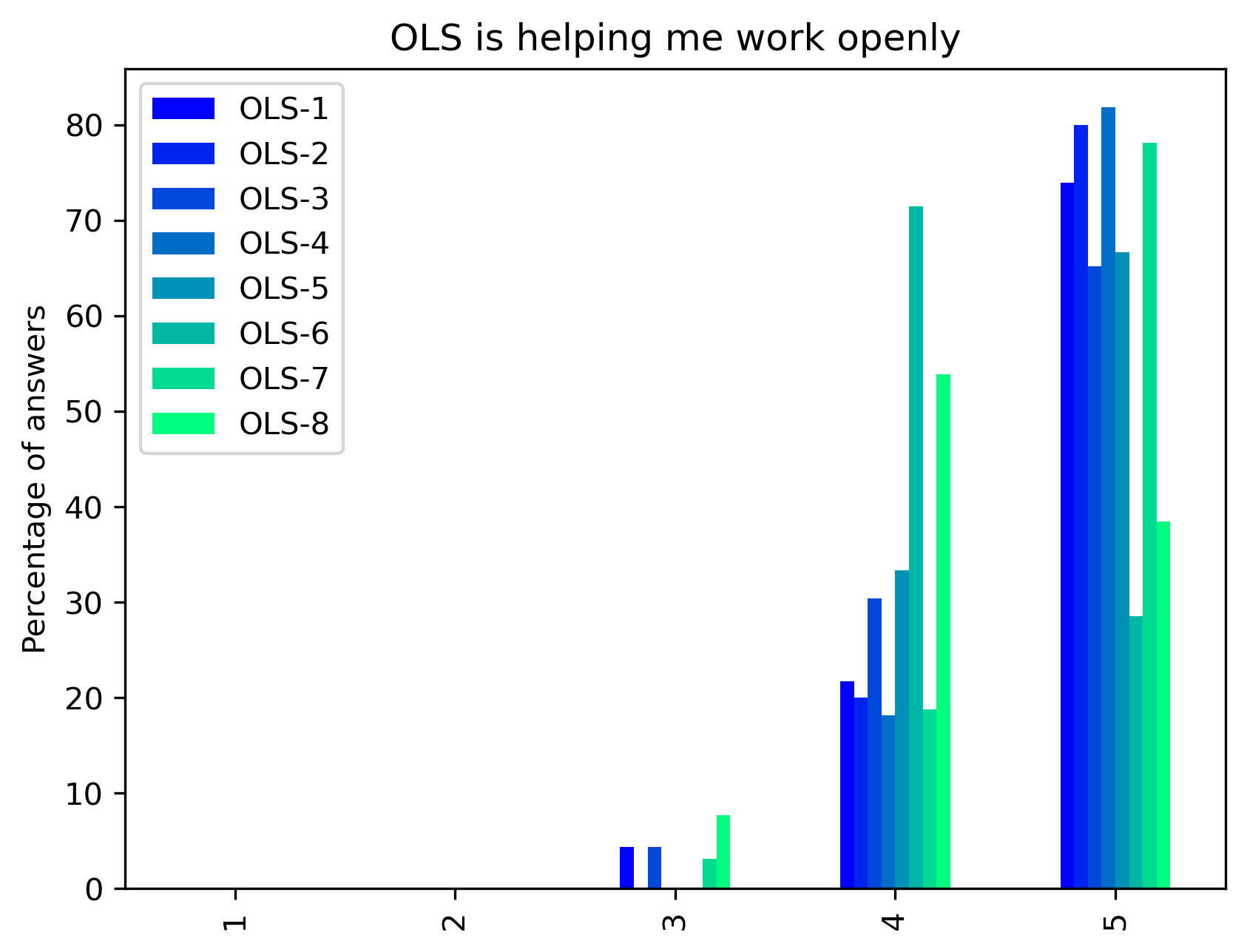
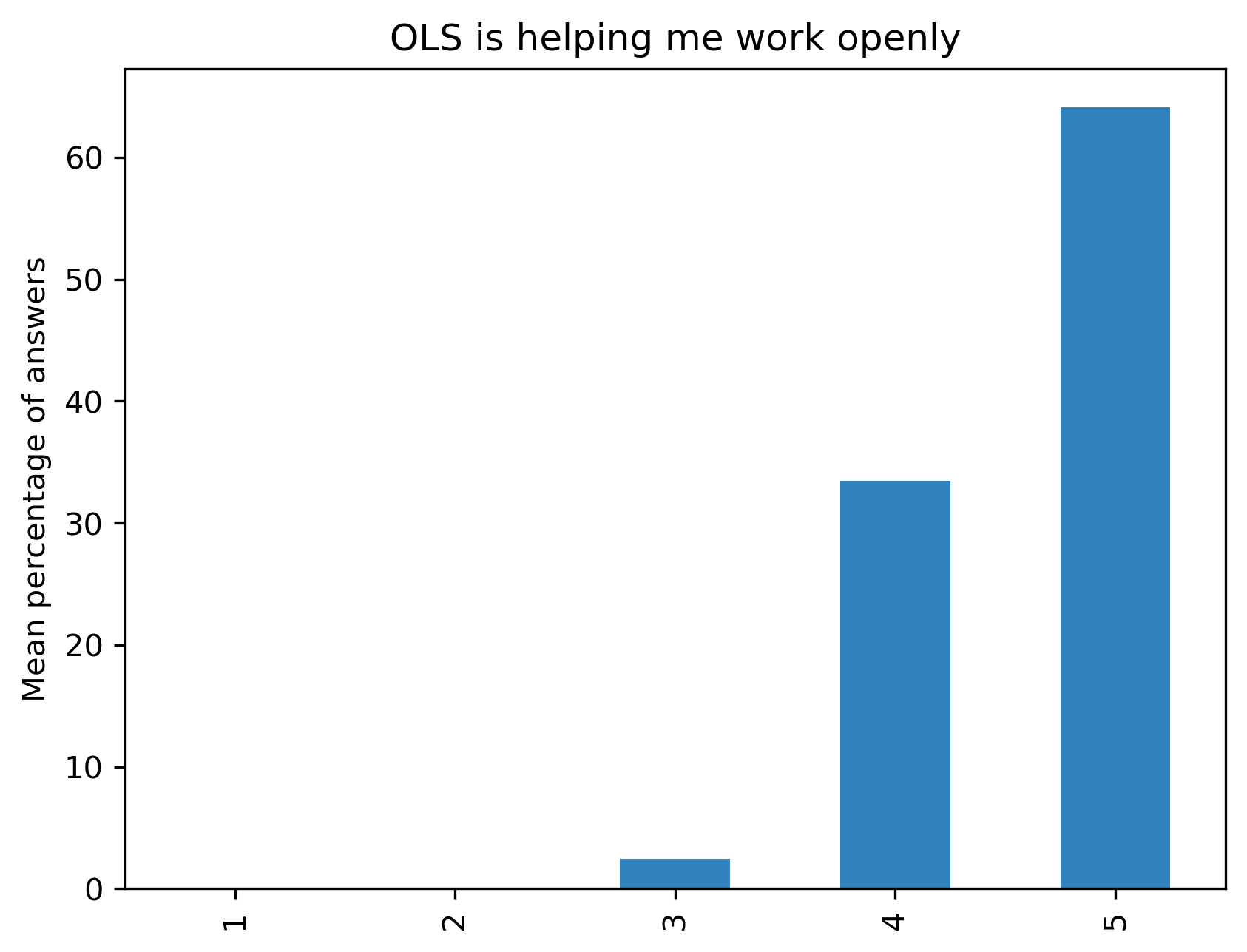
“OLS is helping me work openly”#
Range from 1 (Completely disagree) to 5 (Completely agree) - Percentage of answers
participant_mid_q1 = {}
other_answer = []
col = "OLS is helping me work openly"
answers = list(range(1, 6))
for c in participant_mid_df:
participant_mid_q1[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q1_df = pd.DataFrame.from_dict(participant_mid_q1)
participant_mid_q1_df = 100 * participant_mid_q1_df / participant_mid_q1_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q1_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q1_df.plot.bar(ax=ax, colormap=colors['participant_colormap'])
plt.ylabel('Percentage of answers')
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q1_df.mean(axis=1).plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Mean percentage of answers')
t = plt.title(col)
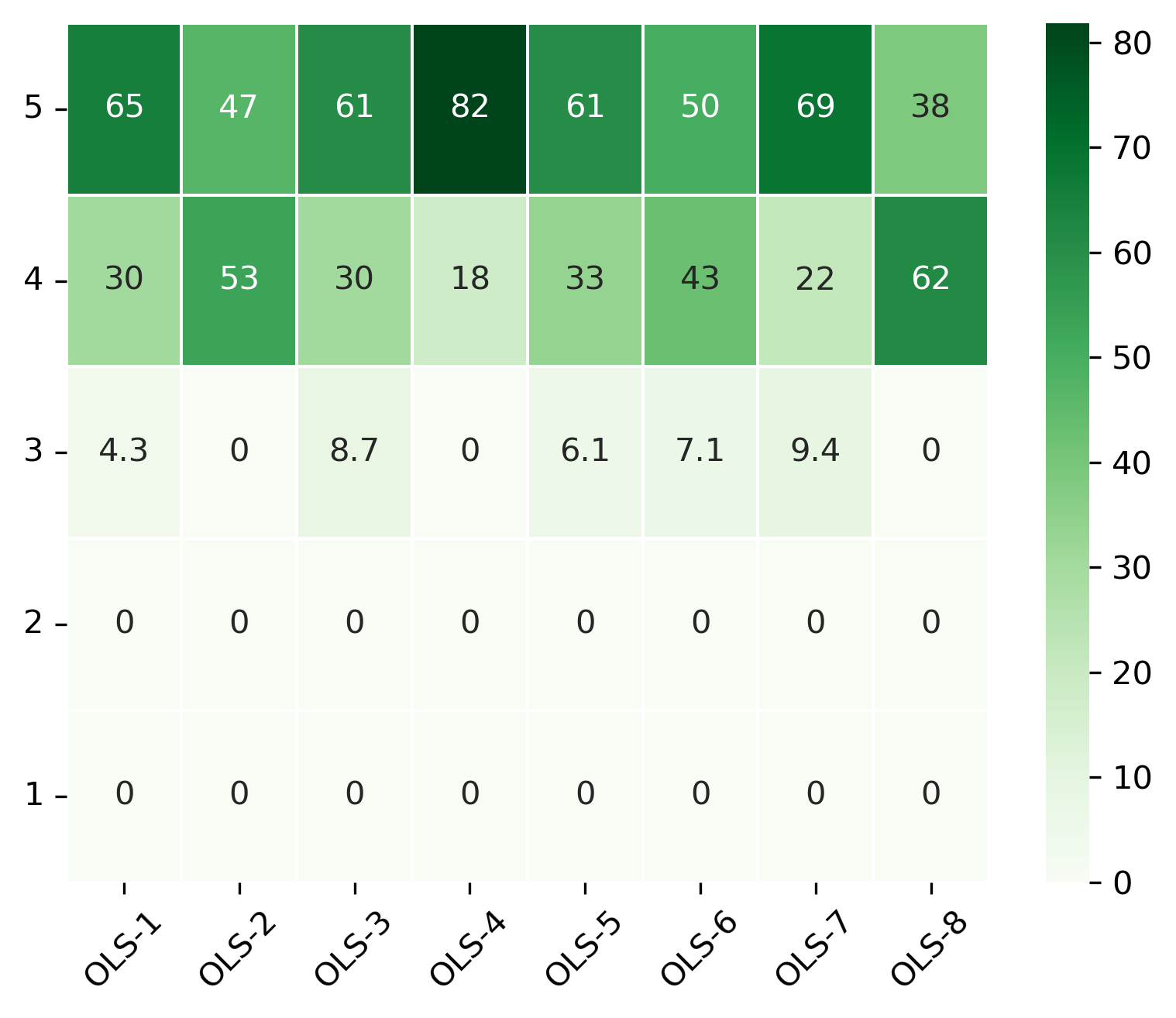
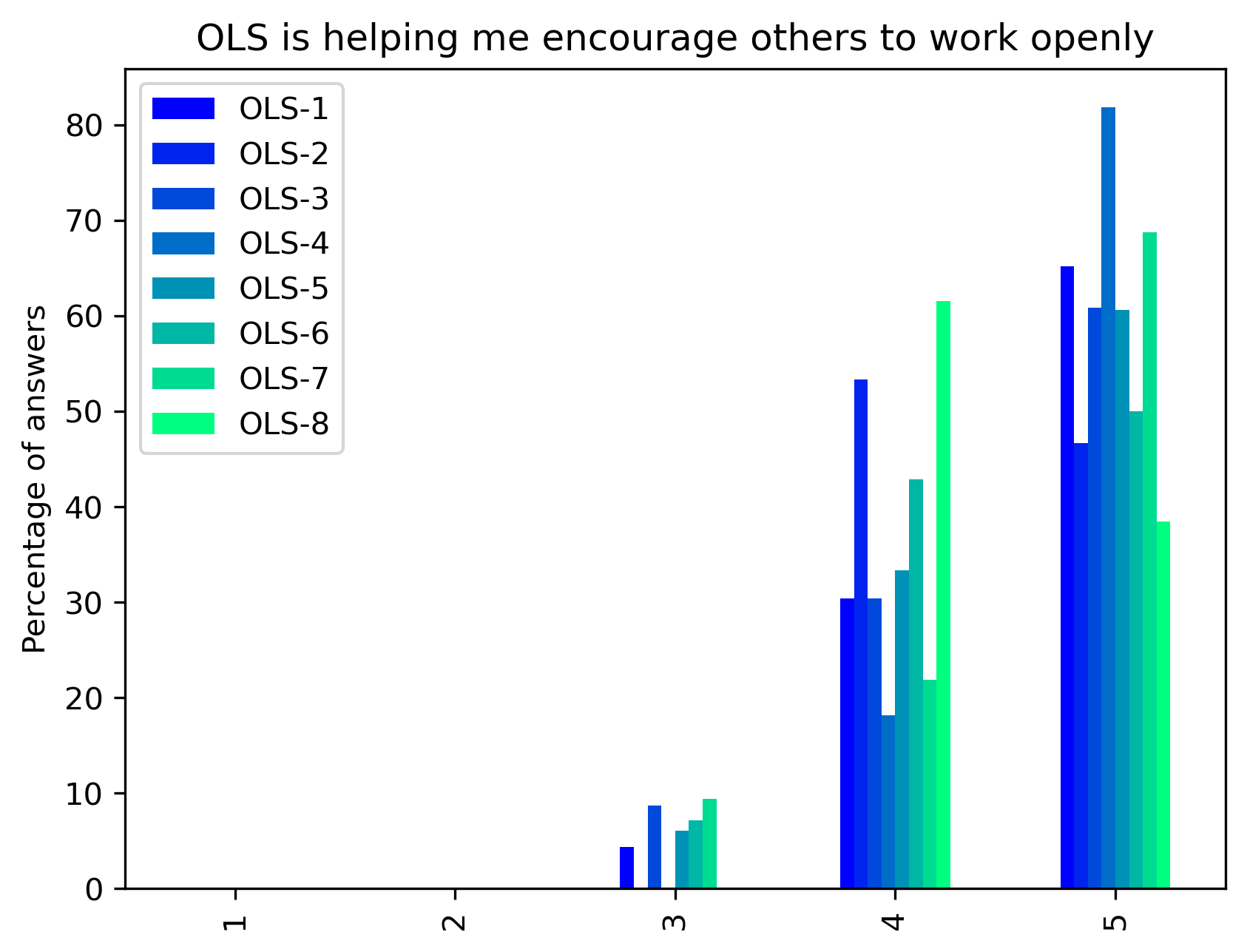
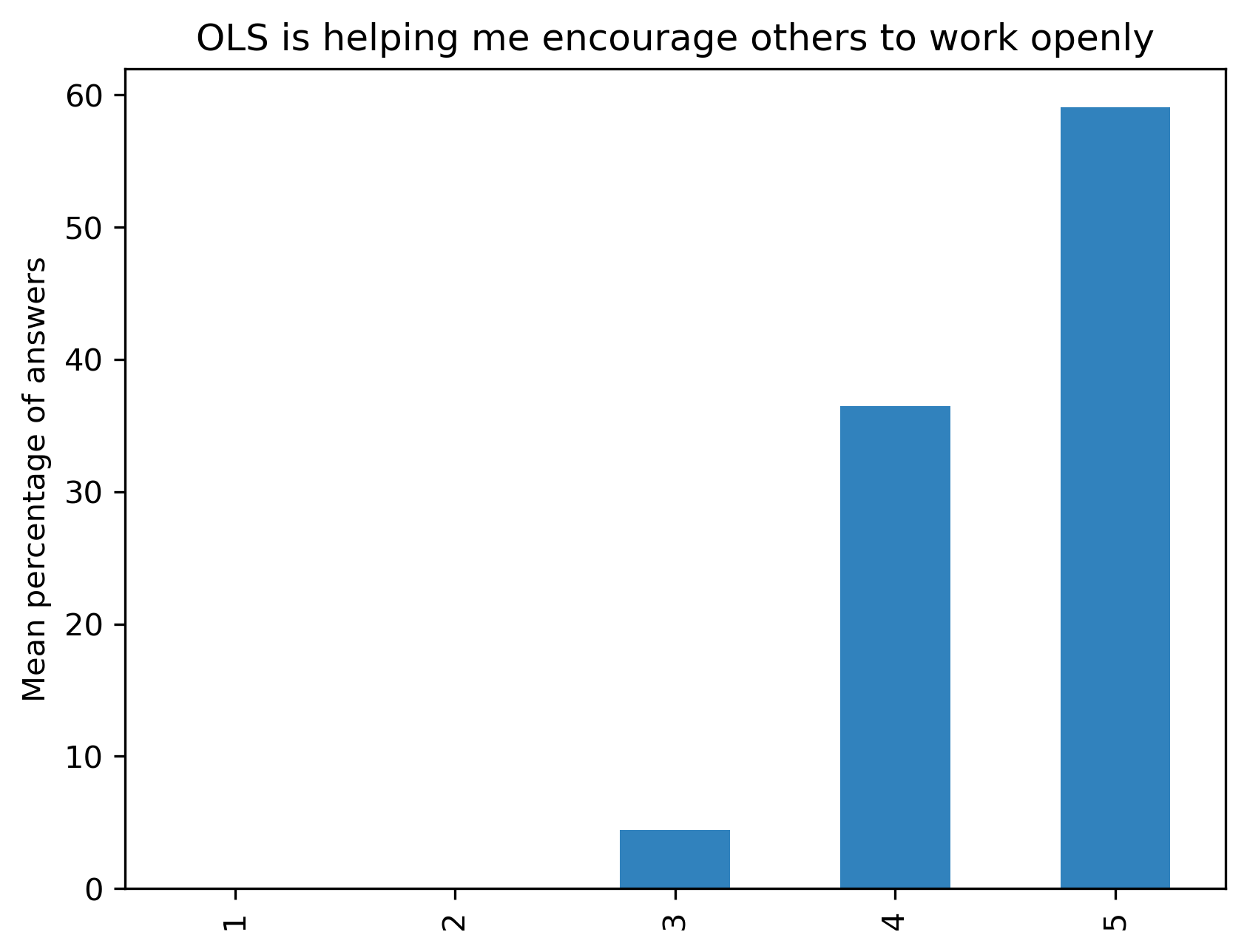
“OLS is helping me encourage others to work openly”#
Range from 1 (Completely disagree) to 5 (Completely agree) - Percentage of answers
participant_mid_q2 = {}
other_answer = []
col = "OLS is helping me encourage others to work openly"
answers = list(range(1, 6))
for c in participant_mid_df:
participant_mid_q2[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q2_df = pd.DataFrame.from_dict(participant_mid_q2)
participant_mid_q2_df = 100 * participant_mid_q2_df / participant_mid_q2_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q2_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q2_df.plot.bar(ax=ax, colormap=colors['participant_colormap'])
plt.ylabel('Percentage of answers')
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q2_df.mean(axis=1).plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Mean percentage of answers')
t = plt.title(col)
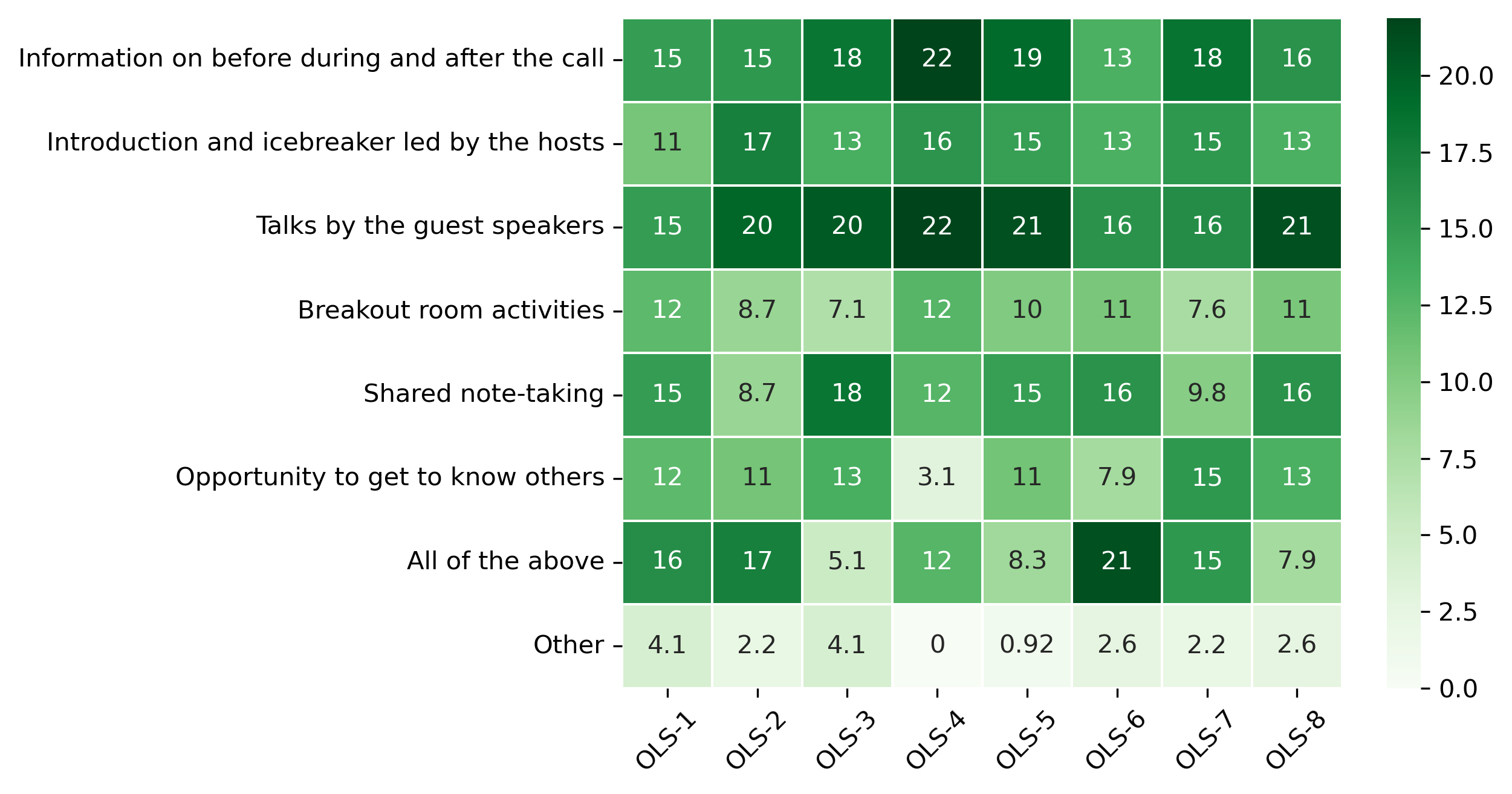
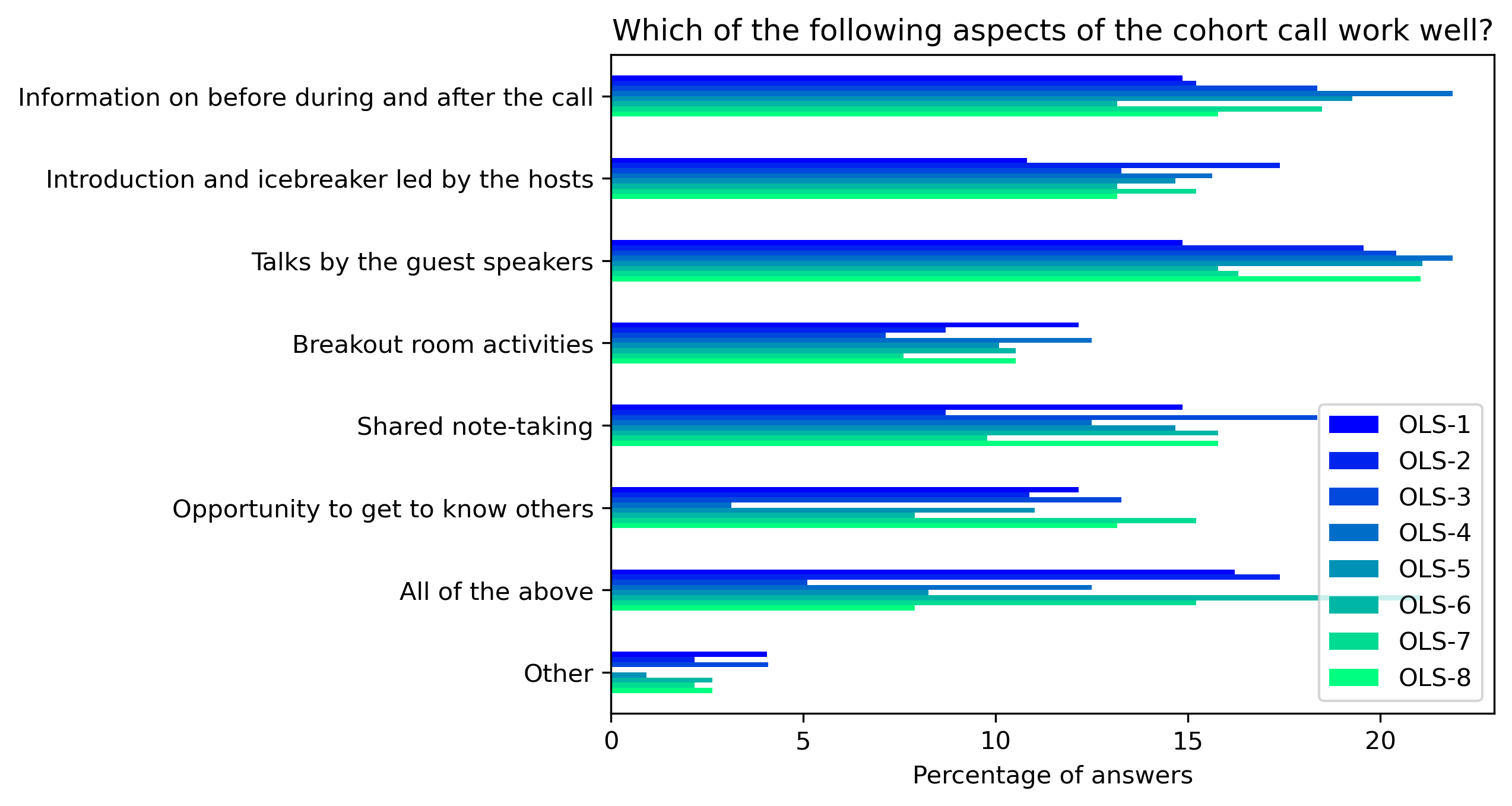
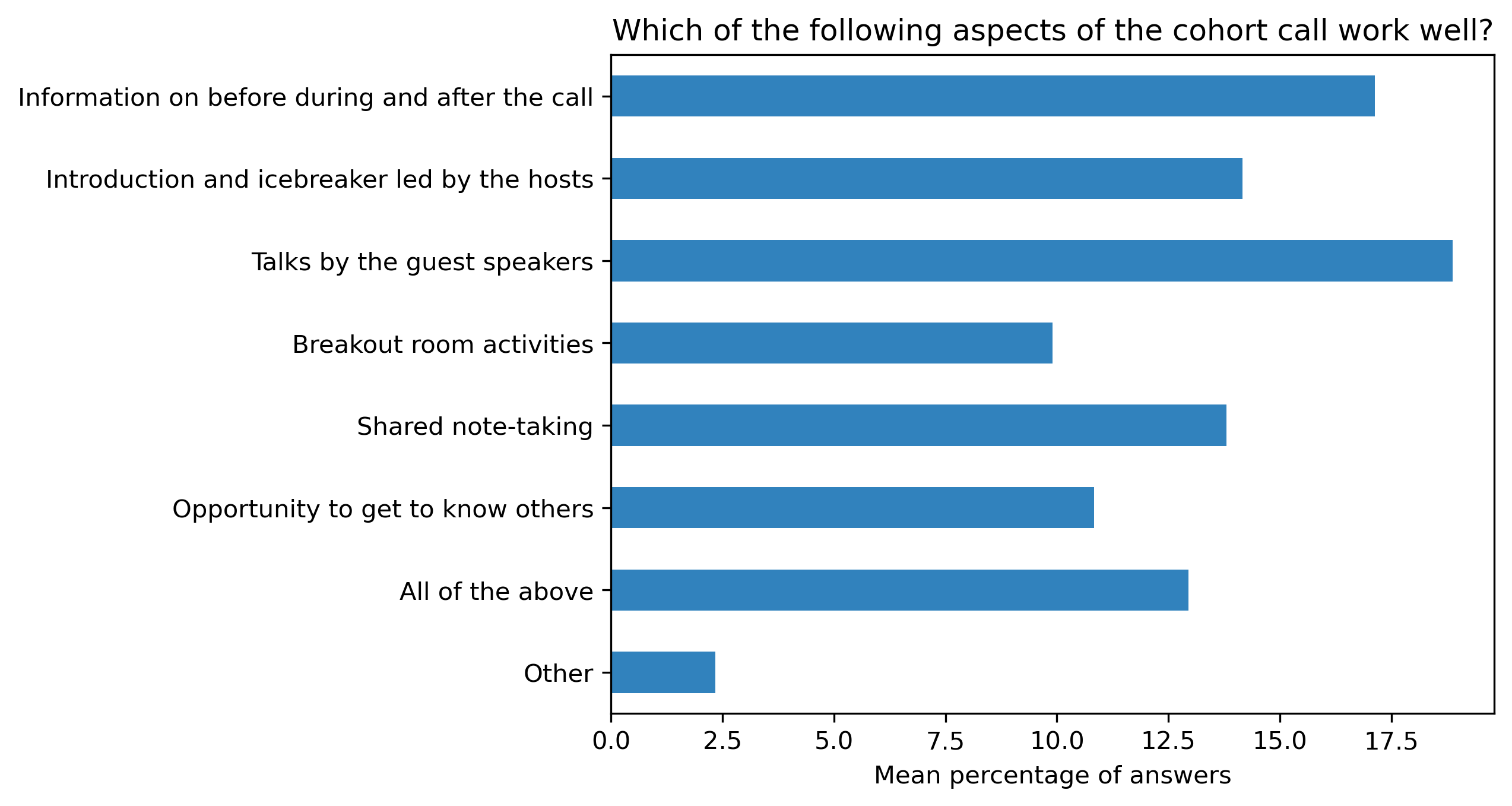
“Which of the following aspects of the cohort call work well?”#
participant_mid_q3 = {}
other_answer = []
col = "Which of the following aspects of the cohort call work well?"
answers = [
"Information on before during and after the call",
"Introduction and icebreaker led by the hosts",
"Talks by the guest speakers",
"Breakout room activities",
"Shared note-taking",
"Opportunity to get to know others",
"All of the above",
"Other"]
for c in participant_mid_df:
participant_mid_q3[c], oa = get_mcq_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q3_df = pd.DataFrame.from_dict(participant_mid_q3)
participant_mid_q3_df = 100 * participant_mid_q3_df / participant_mid_q3_df.sum()
Other answers:
other_answer
['Side chats on twitter by members.',
"I like the engagement feeling. It's not a webinar where one can fall asleep",
'Shared insights by the mentor on the answers shared by the mentee',
"Wasn't the shared note taking on HackMD? It's also on gDocs?",
'Written breakout room activities',
'Having spoken and written spaces',
'Recording the call and making it available on YouTube',
'Mentorship by mentors',
'Love the trainings!',
'calls are recorded so i can watch later (I am in an odd timezone)',
'practice how to work with other people',
'Learning from others ',
'Providing recordings/notes of calls in a timely manner afterwards. ']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q3_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q3_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q3_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
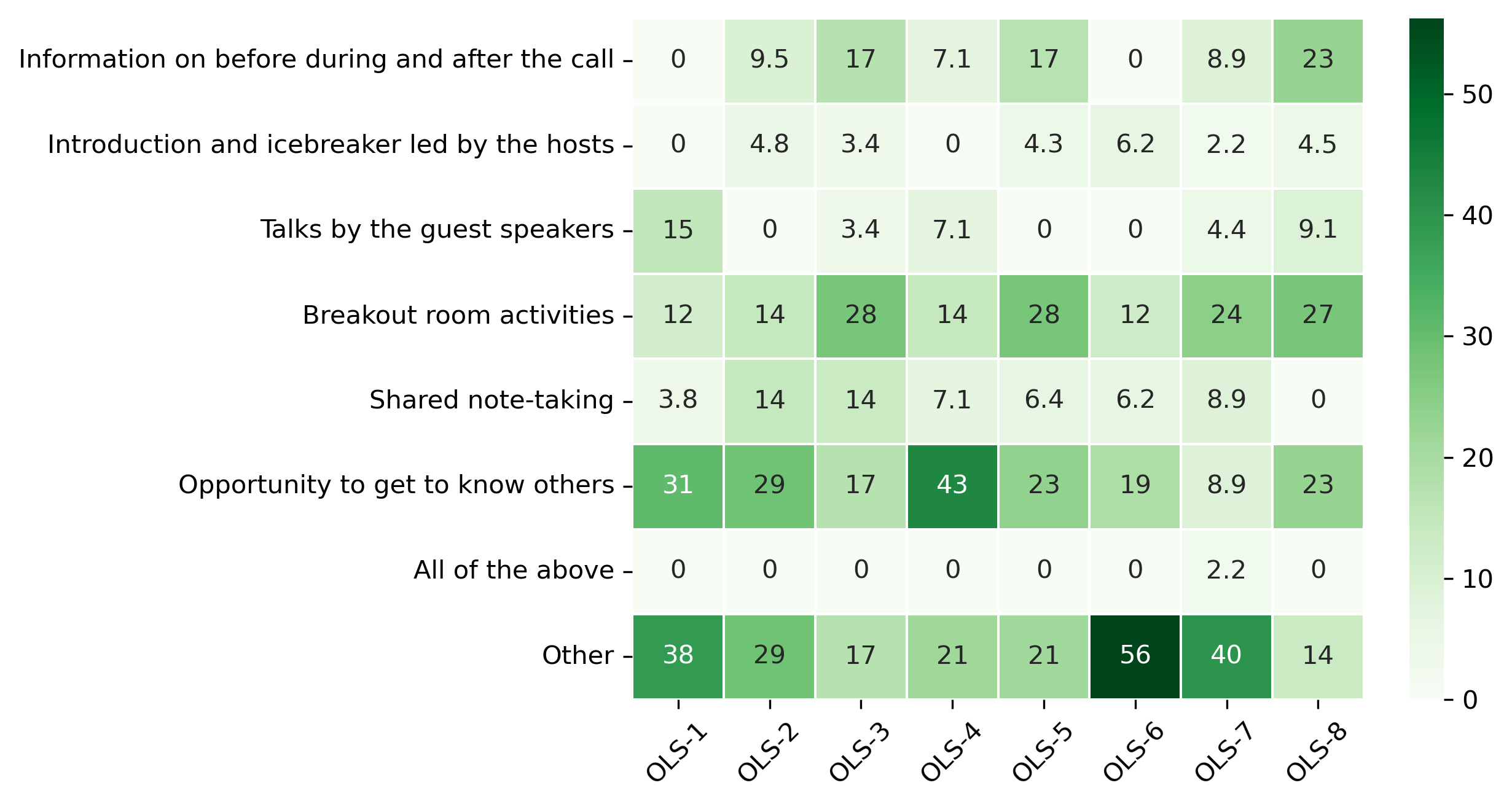
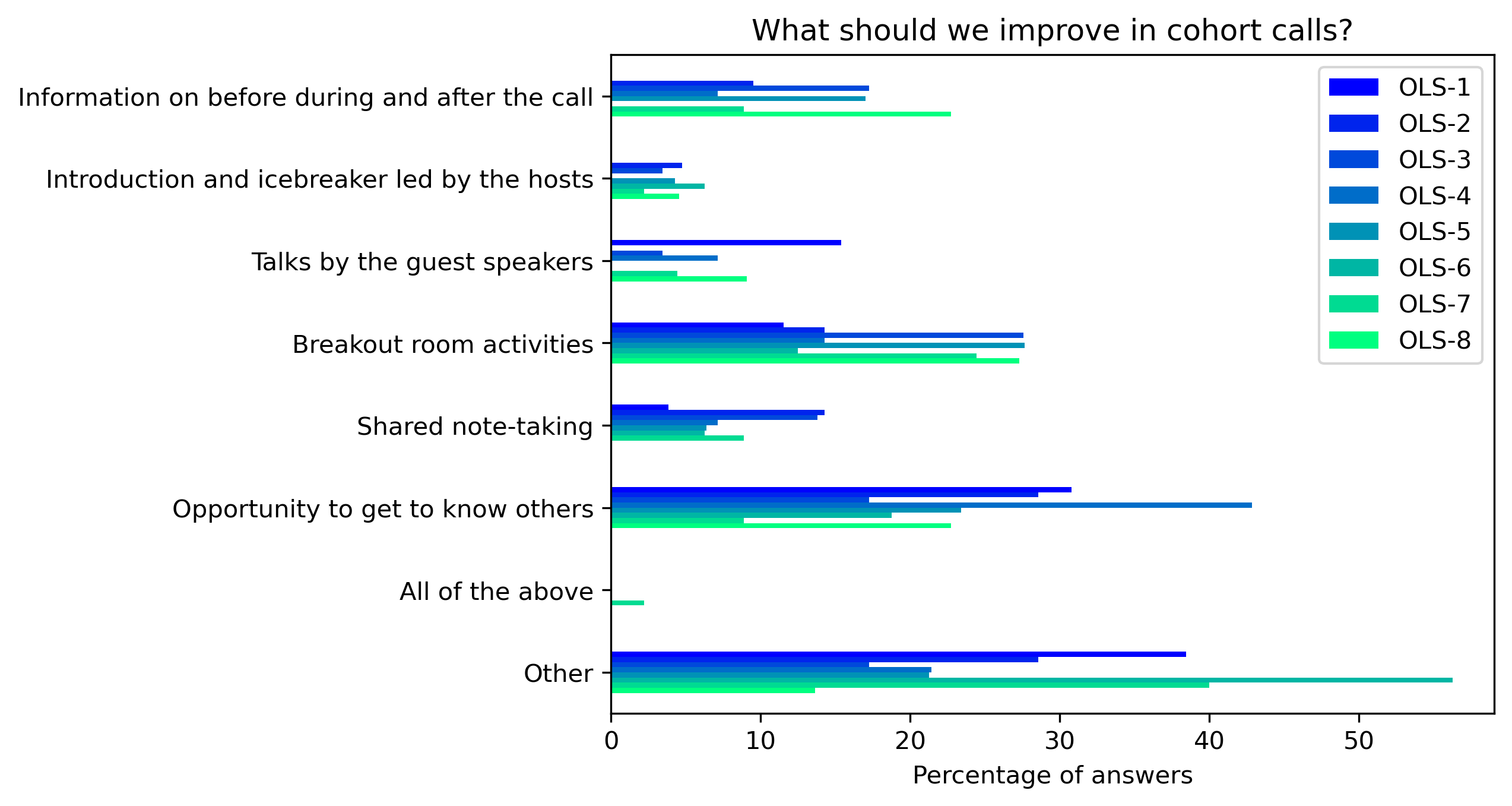
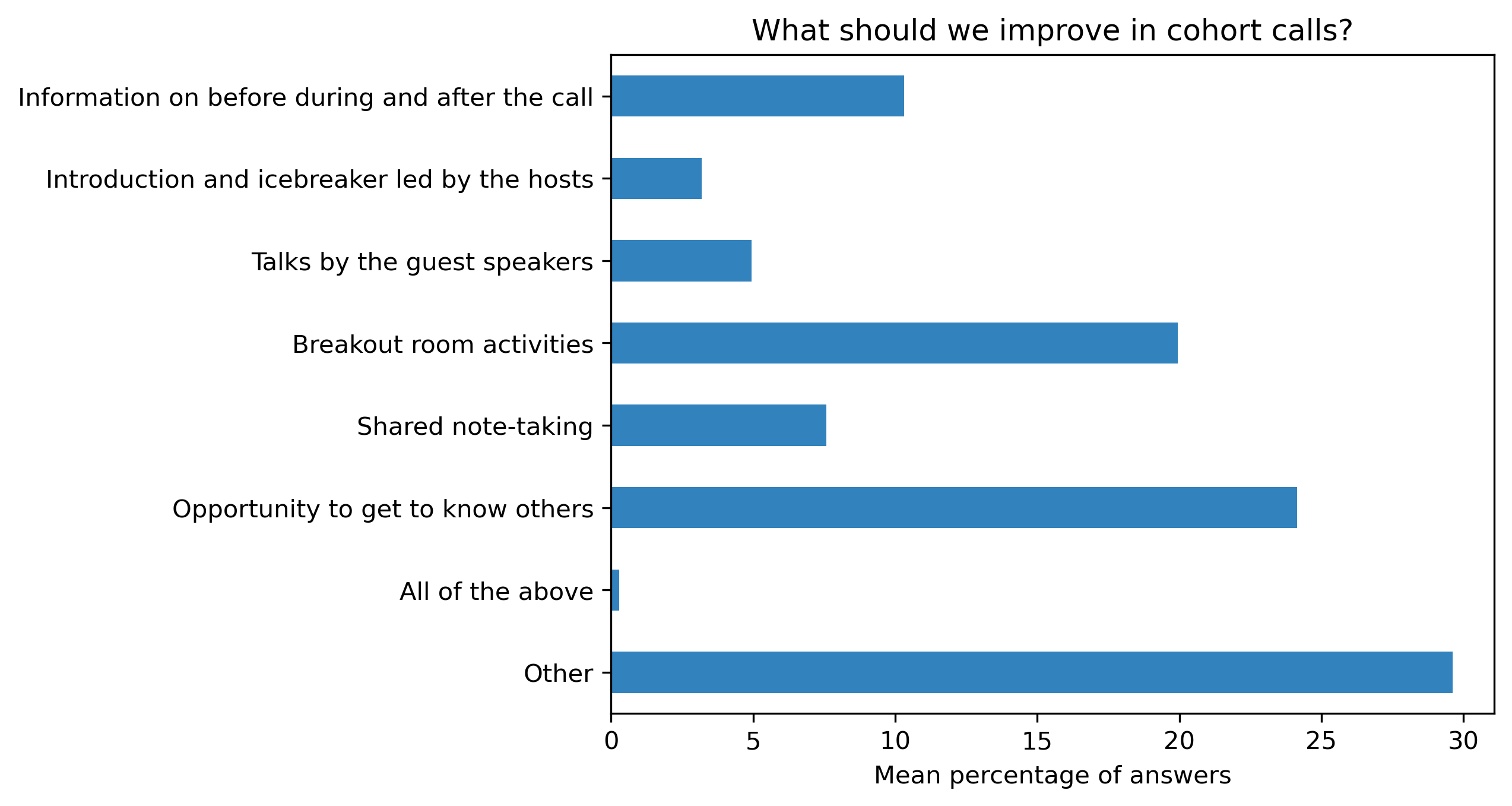
“What should we improve in cohort calls?”#
participant_mid_q4 = {}
other_answer = []
col = "What should we improve in cohort calls?"
answers = [
"Information on before during and after the call",
"Introduction and icebreaker led by the hosts",
"Talks by the guest speakers",
"Breakout room activities",
"Shared note-taking",
"Opportunity to get to know others",
"All of the above",
"Other"]
for c in participant_mid_df:
participant_mid_q4[c], oa = get_mcq_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q4_df = pd.DataFrame.from_dict(participant_mid_q4)
participant_mid_q4_df = 100 * participant_mid_q4_df / participant_mid_q4_df.sum()
Other answers:
other_answer
['',
'breakout room instruction',
'I have no suggestions',
'Cohort calls were rather long and it was difficult to find time to participate in',
'so I usually saw the Youtube videos. I guess I would participate more often if calls were shorter.',
'shared note taking has been difficult on hack md',
'sometimes at the beginning it was hard to find all of the links to assignments',
'so it would be nice to have those all in the schedule too',
'No suggestions in this regard.',
'',
'nothing ',
'The talks are very interesting',
'More time for questions for the speakers',
'Everything is fine',
'Nothing',
'Everything works fine:)',
'',
'na',
'Ocasionally I lioked for the recording and it was not up after a few days but it is completely understandable ',
'to add extra accountability and make it easier to see ways to collaborate/assist?',
'regular project updates',
'Maybe more discussions/talks by the experts',
'Maybe include brief',
'Is there a way to set automated email for checking in individually with different projects (personal email asking how they are doing?)',
'I have not been getting much out of the breakout room activities yet. I think that meeting with experts there will be more opportunity to get to know other folks in the cohort',
'Timming. Es mucho para hacer en poco tiempo.',
'The timing',
'narrative and speed of the calls has been good for me! I o',
'None ',
'',
'Timing',
'Maybe read the ice breaker responses for more acknowledgment of responses. ',
'nothing',
'none',
'it works',
'Nonr',
"It's really great! I've loved the speakers and have learnt so much. ",
'-',
'None of the above ',
'scheduling',
'Add more time for break out room activities ',
'maybe let some presentations be longer',
'Time the calls are scheduled to start ',
'Nothing in particular comes to mind',
'Which of the following aspects of the cohort call work well',
'Break out rooms are often too short to get to know other people',
'more in depth',
'nothing as of now',
'Translation in french ',
'short videos to be shared with students instead of online face to face talks (e-meetings)',
'One hour or 30mins reminders before cohort calls',
'Adding more time for breakout rooms',
"Haven't attended much. Was seeing mainly in Youtube",
'so would like to skip the question.',
'Sharing recording transcripts also would be helpful. ',
'',
'I think is more my difficulty to adapt. You are making and excellent job!']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q4_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q4_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
plt.title(col)
#plt.savefig('../', bbox_inches='tight')
Text(0.5, 1.0, 'What should we improve in cohort calls?')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q4_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
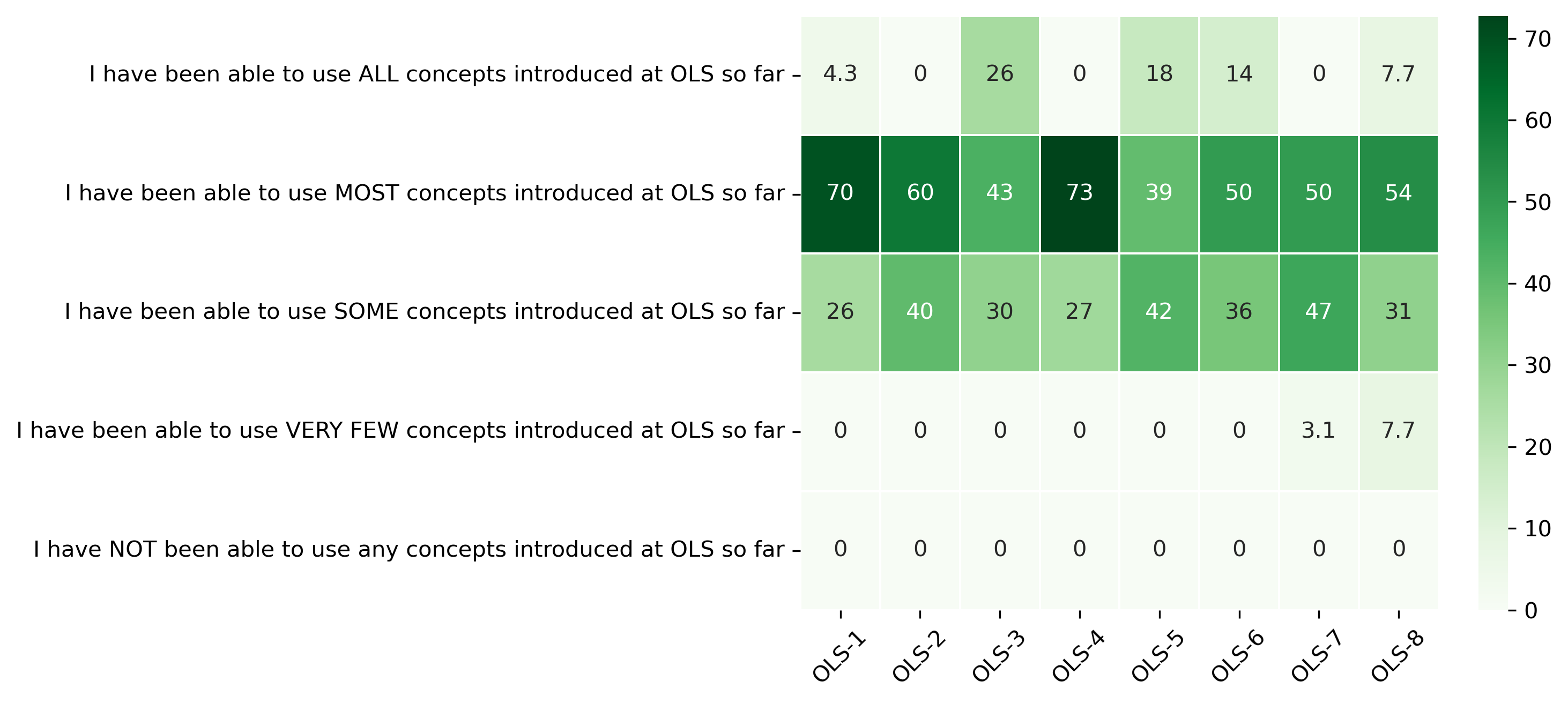
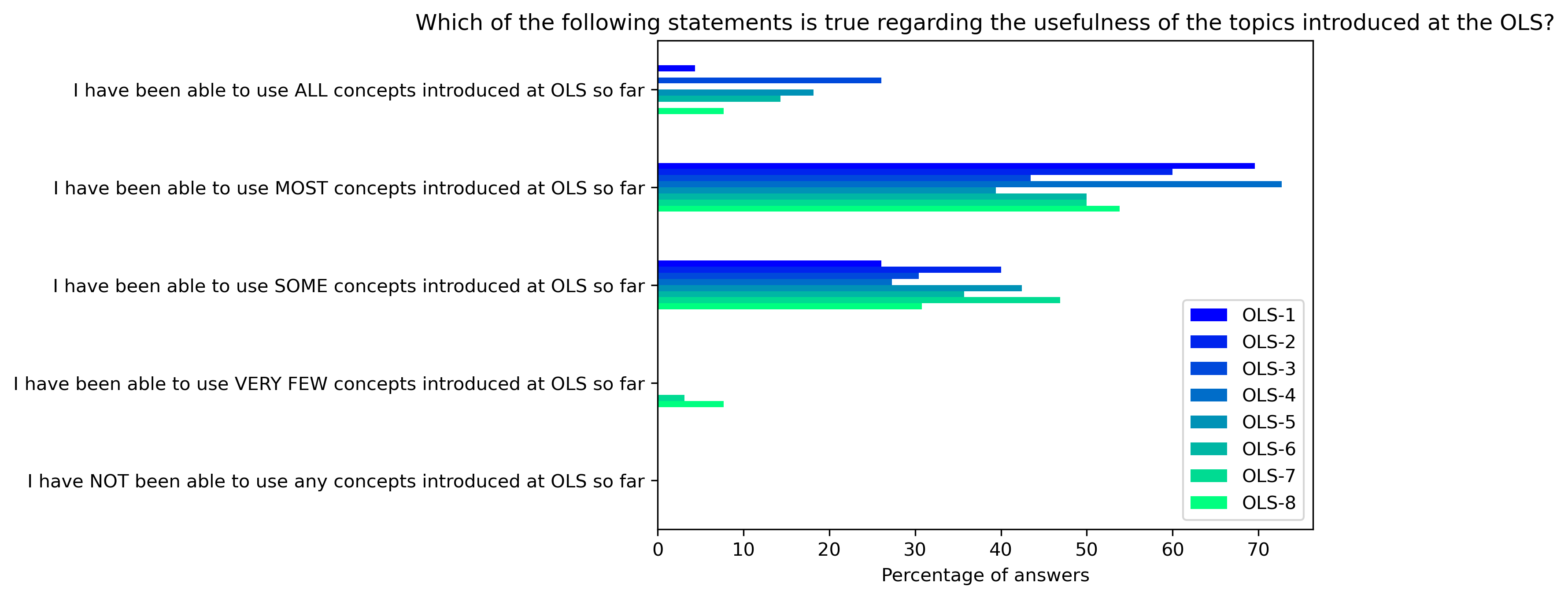
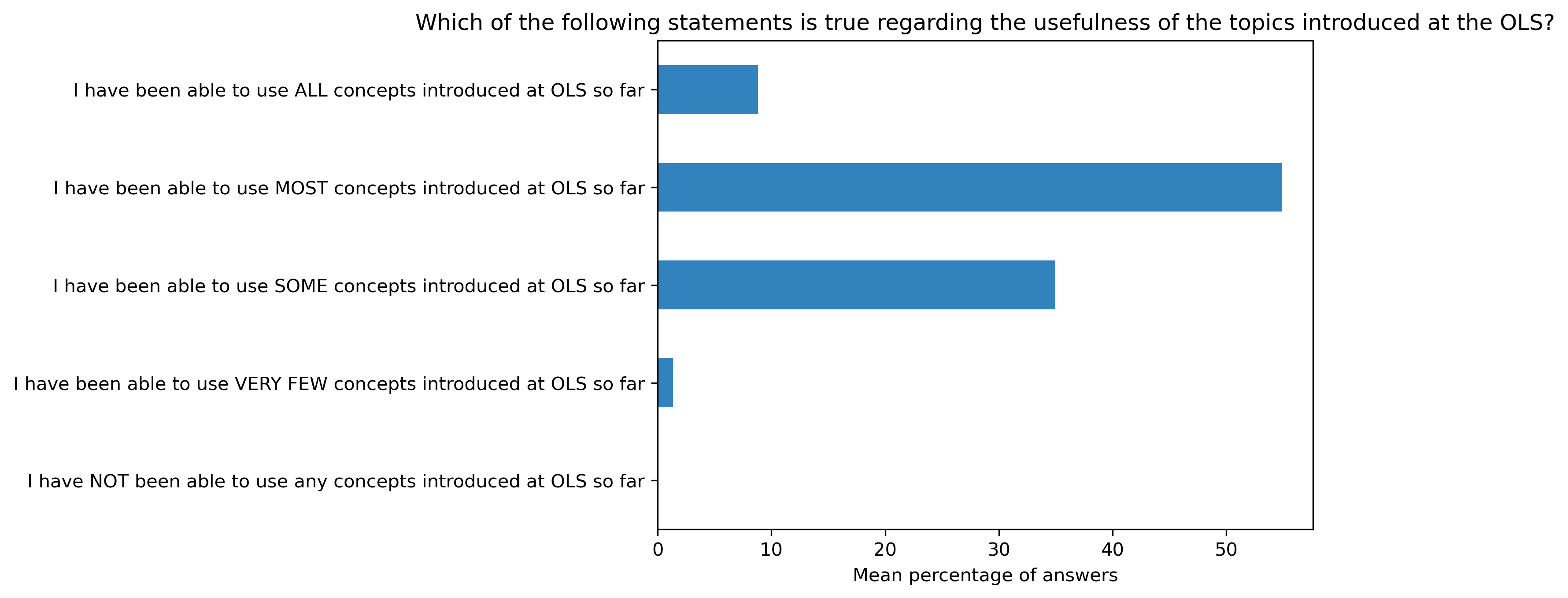
“Which of the following statements is true regarding the usefulness of the topics introduced at the OLS?”#
participant_mid_q5 = {}
other_answer = []
col = "Which of the following statements is true regarding the usefulness of the topics introduced at the OLS?"
answers = [
"I have been able to use ALL concepts introduced at OLS so far",
"I have been able to use MOST concepts introduced at OLS so far",
"I have been able to use SOME concepts introduced at OLS so far",
"I have been able to use VERY FEW concepts introduced at OLS so far",
"I have NOT been able to use any concepts introduced at OLS so far"]
for c in participant_mid_df:
participant_mid_q5[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q5_df = pd.DataFrame.from_dict(participant_mid_q5)
participant_mid_q5_df = 100 * participant_mid_q5_df / participant_mid_q5_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q5_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q5_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
plt.title(col)
#plt.savefig('../', bbox_inches='tight')
Text(0.5, 1.0, 'Which of the following statements is true regarding the usefulness of the topics introduced at the OLS?')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q5_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
plt.title(col)
Text(0.5, 1.0, 'Which of the following statements is true regarding the usefulness of the topics introduced at the OLS?')
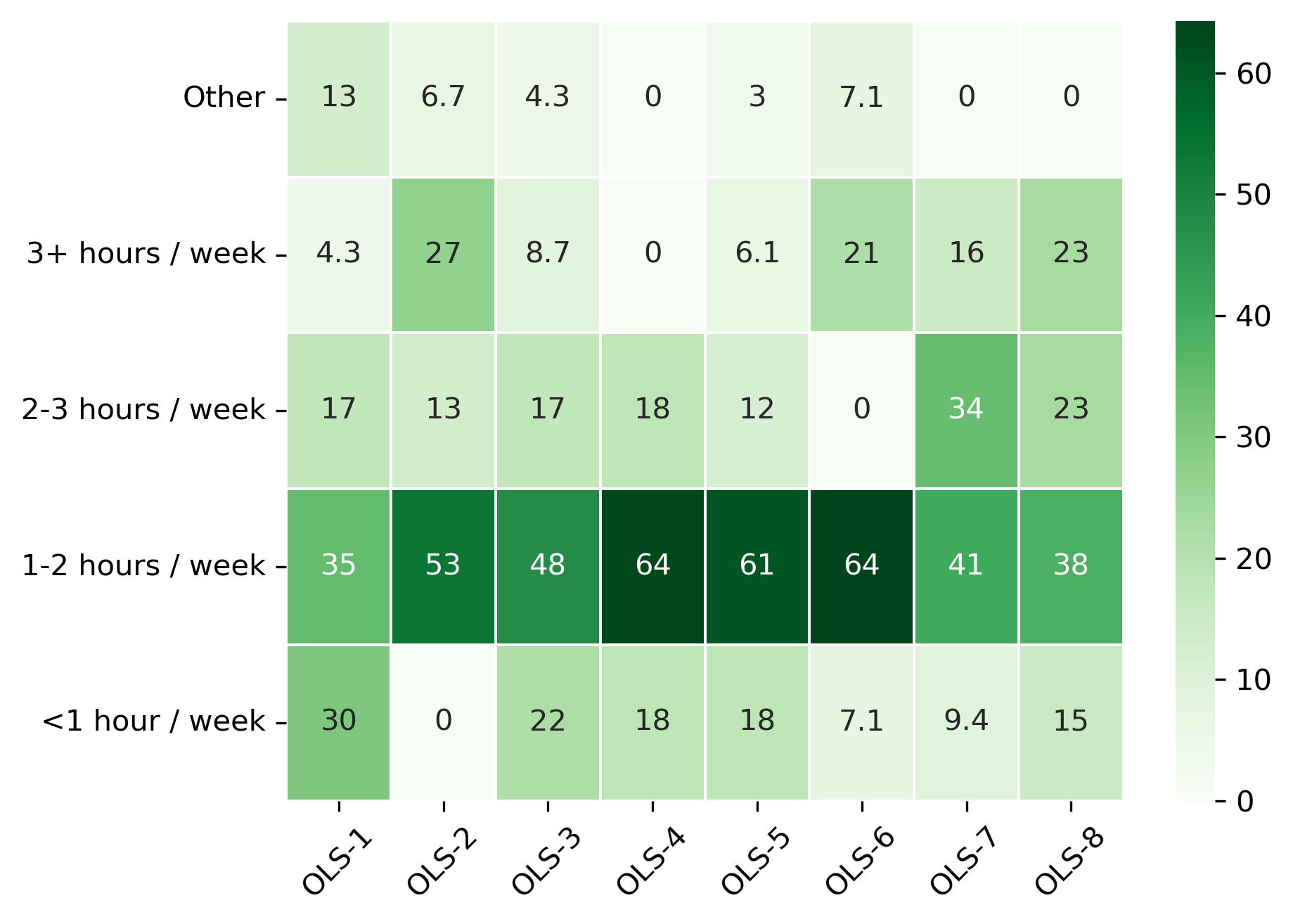
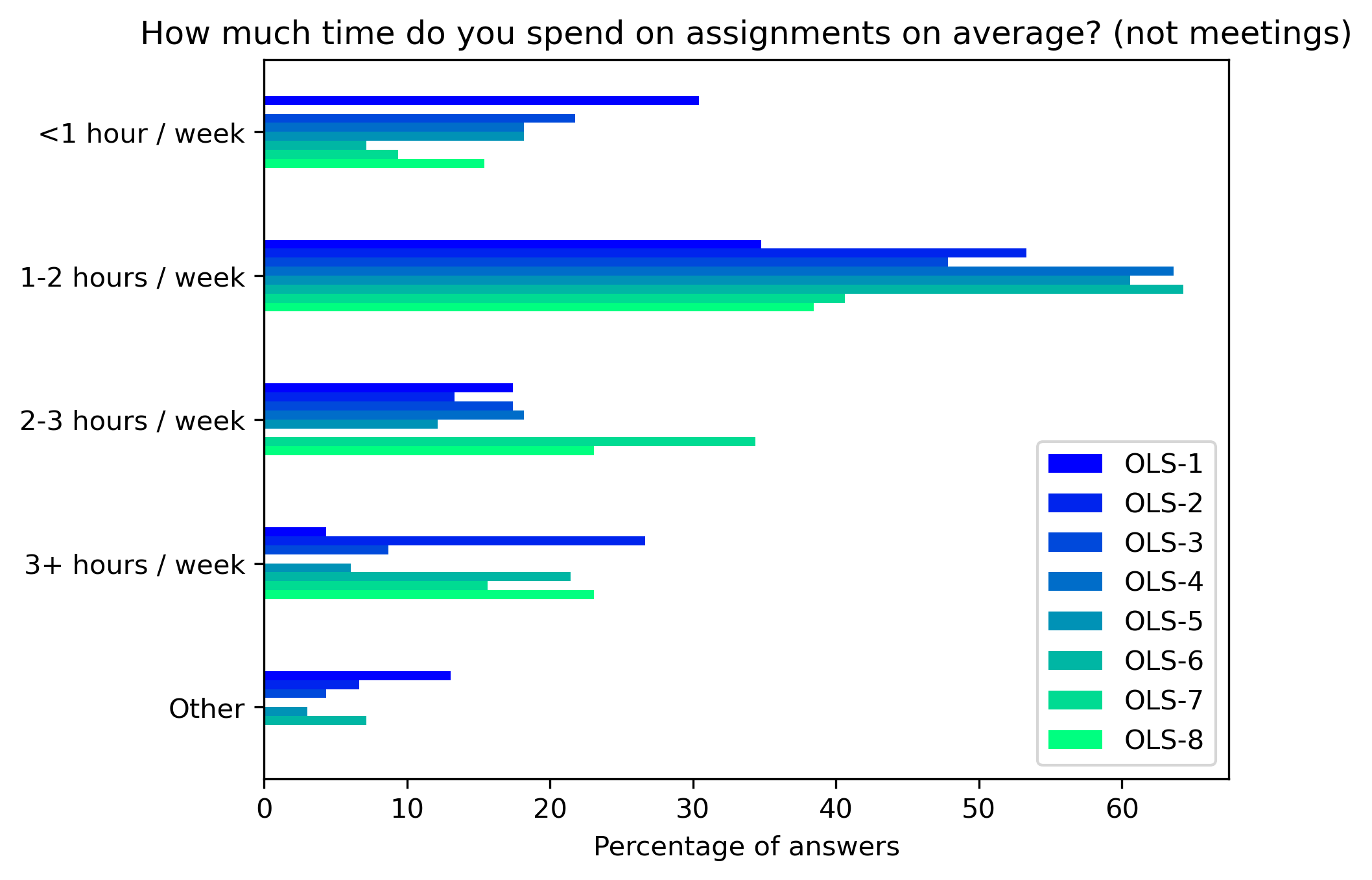
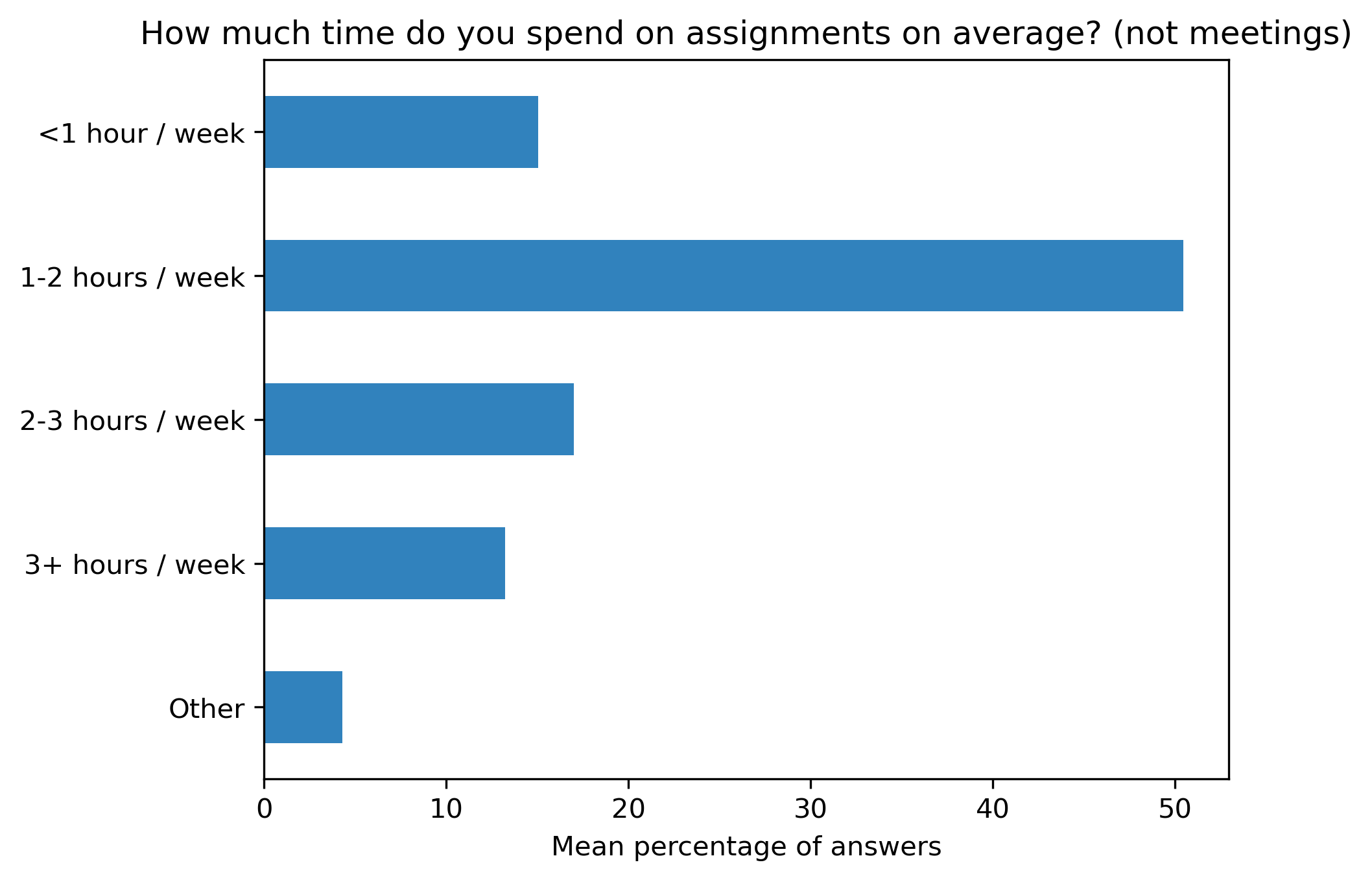
“How much time do you spend on assignments on average? (not meetings)”#
participant_mid_q6 = {}
other_answer = []
col = "How much time do you spend on assignments on average? (not meetings)"
answers = [
"<1 hour / week",
"1-2 hours / week",
"2-3 hours / week",
"3+ hours / week",
"Other"]
for c in participant_mid_df:
participant_mid_q6[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q6_df = pd.DataFrame.from_dict(participant_mid_q6)
participant_mid_q6_df = 100 * participant_mid_q6_df / participant_mid_q6_df.sum()
Other answers:
other_answer
['I usually read more on the assignments and materials during my free hours. I am not sure how many hours I spend on them though.',
"As I'm severely behind schedule with my project work at the moment (extensive work travelling followed by the current chaotic situation), I can't answer this and the previous question reliably. I'm sure I'll use (almost) ALL the concepts introduced as soon as I'll manage catching up. I've been spending 0-2 hours / week with the assignments, but I would have needed / will need much more time to keep up.",
'1-2 hours / week the weeks before situation got crazy in Spain (first week of March)',
"Hard to say as some weeks were a lot and then some weeks I didn't do the homeworks",
'1 hr / week sometimes + <1 hr / week some time depending upon the commitments or assignments',
'',
'"some" hours when I can, unfortunately not on a regular basis']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q6_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q6_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q6_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
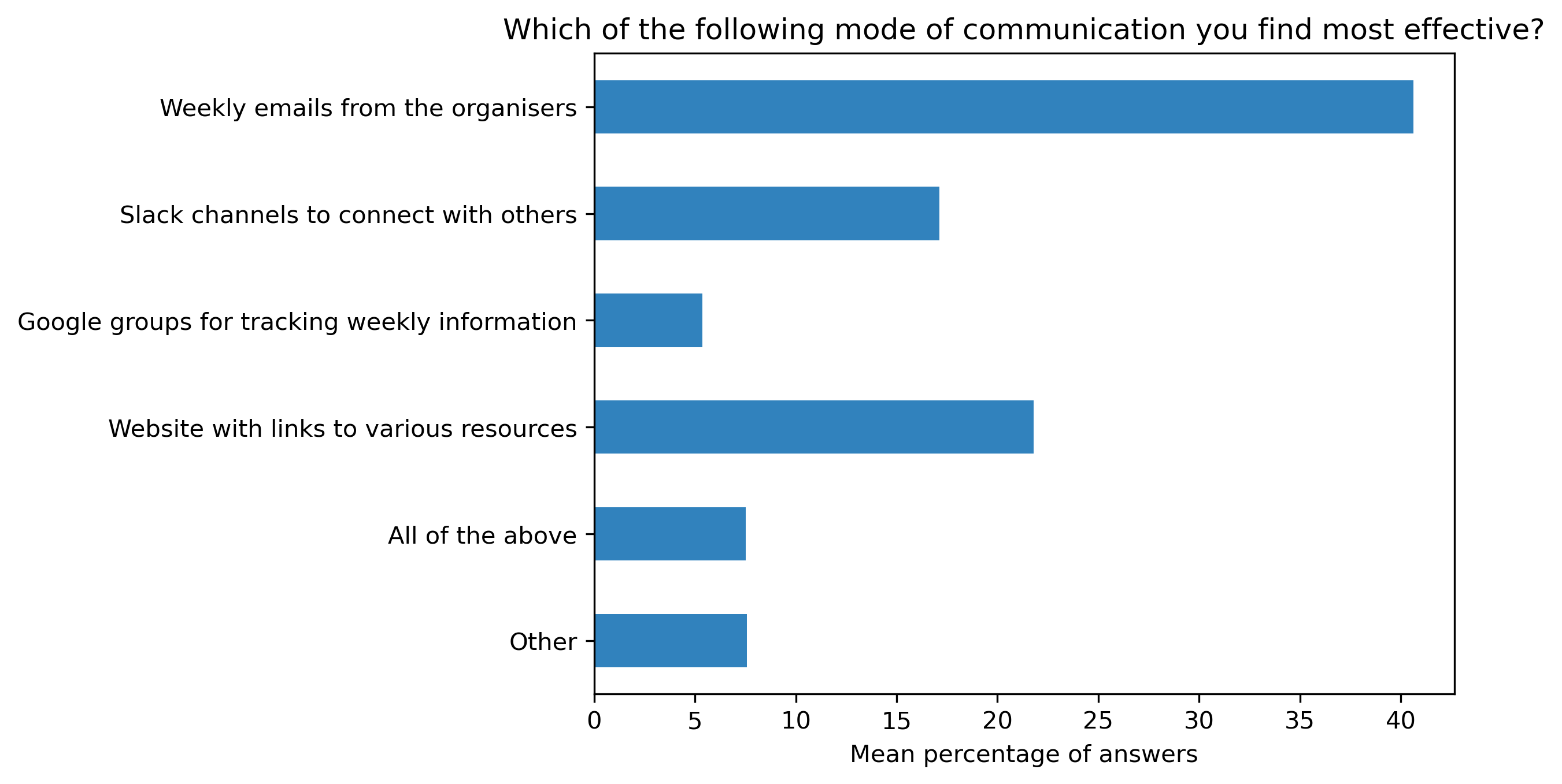
“Which of the following mode of communication you find most effective?”#
participant_mid_q7 = {}
other_answer = []
col = "Which of the following mode of communication you find most effective?"
answers = [
"Weekly emails from the organisers",
"Slack channels to connect with others",
"Google groups for tracking weekly information",
"Website with links to various resources",
"All of the above",
"Other"]
for c in participant_mid_df:
participant_mid_q7[c], oa = get_mcq_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q7_df = pd.DataFrame.from_dict(participant_mid_q7)
participant_mid_q7_df = 100 * participant_mid_q7_df / participant_mid_q7_df.sum()
Other answers:
other_answer
['Gitter channel to connect with others',
'I think there might be too many methods of communication about OLS? Sometimes I have a hard time finding information about something specific',
"especially if it's in a Google Doc from a cohort call. ",
'Slack channel',
'Slack',
'Slack instead of Gitter',
'youtube recorded cohort-calls',
"I didn't use Gitter nor the Google Groups. Slack is pretty useful and the weekly emails too. The website & GitHub are helpful as well.",
'I miss some live/online meetings to get to know people',
'not via tools.',
'Review notes from mentor mentors',
'',
'Whatsapp ',
'OLS Calendar',
'Slack is useful',
'but is a shame that is a free version so lose access to some posts after 90 days. Perhaps could migrate info to open source version',
'Mattermost instead? ']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q7_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
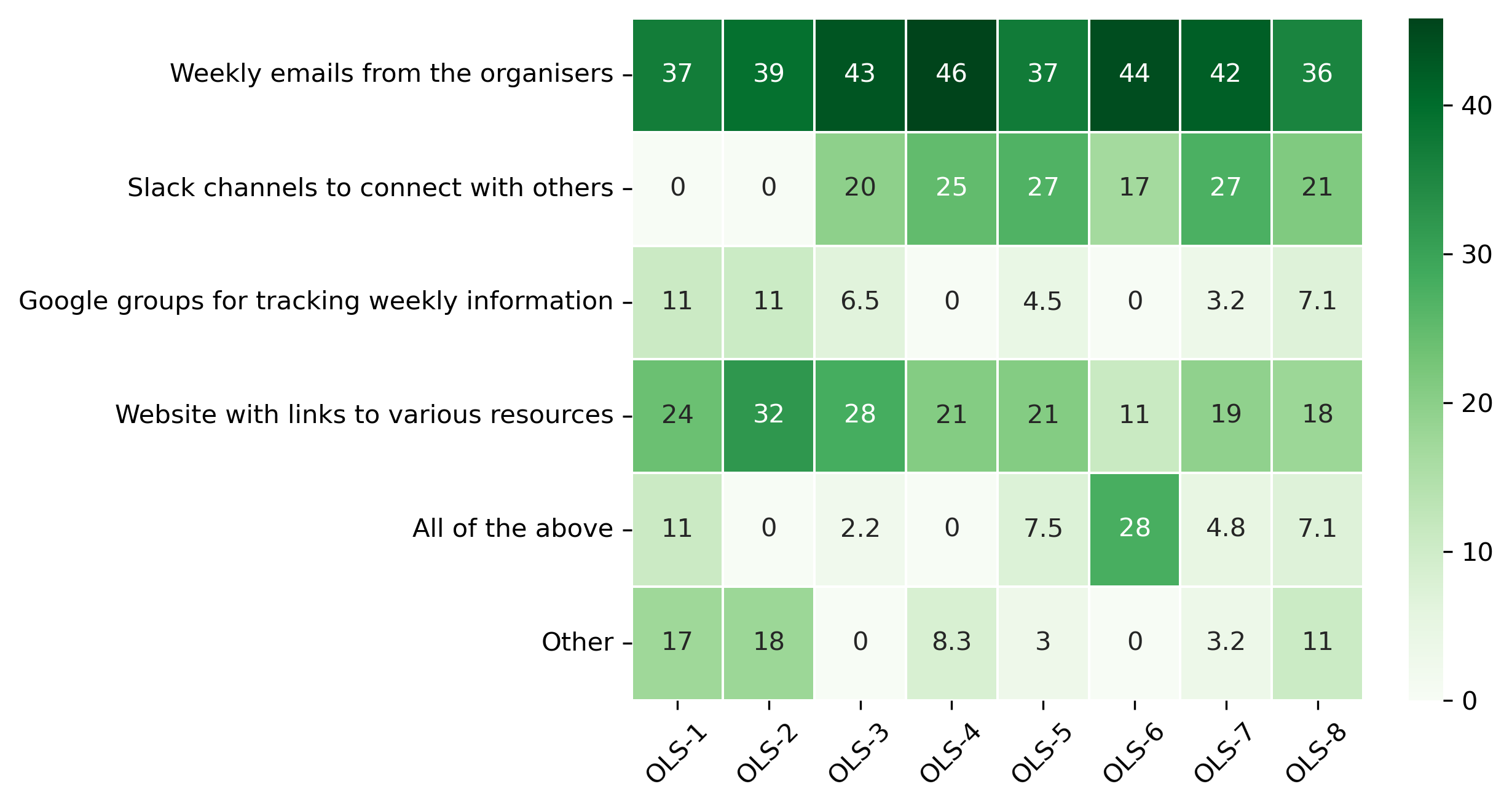
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q7_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
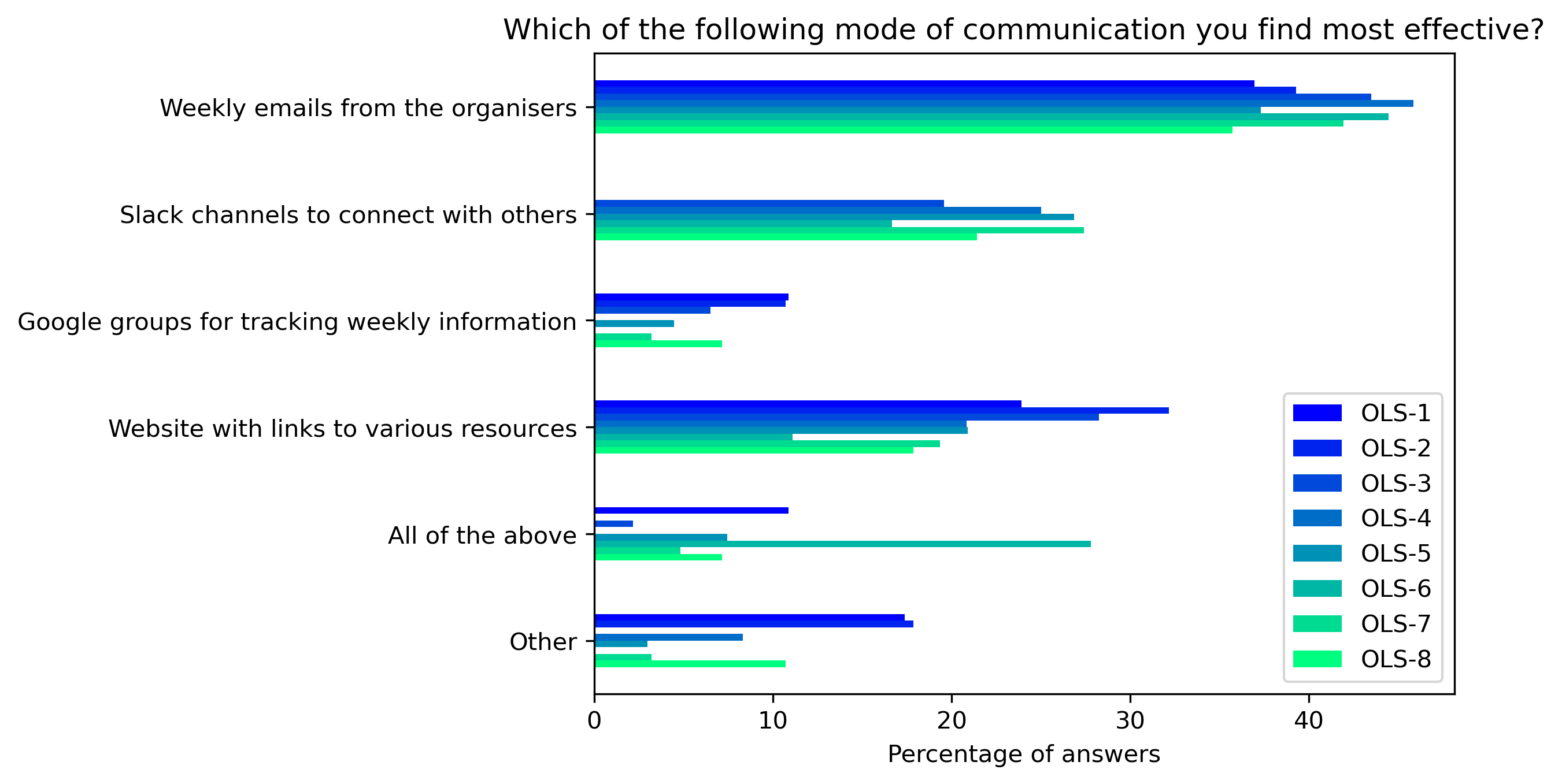
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q7_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
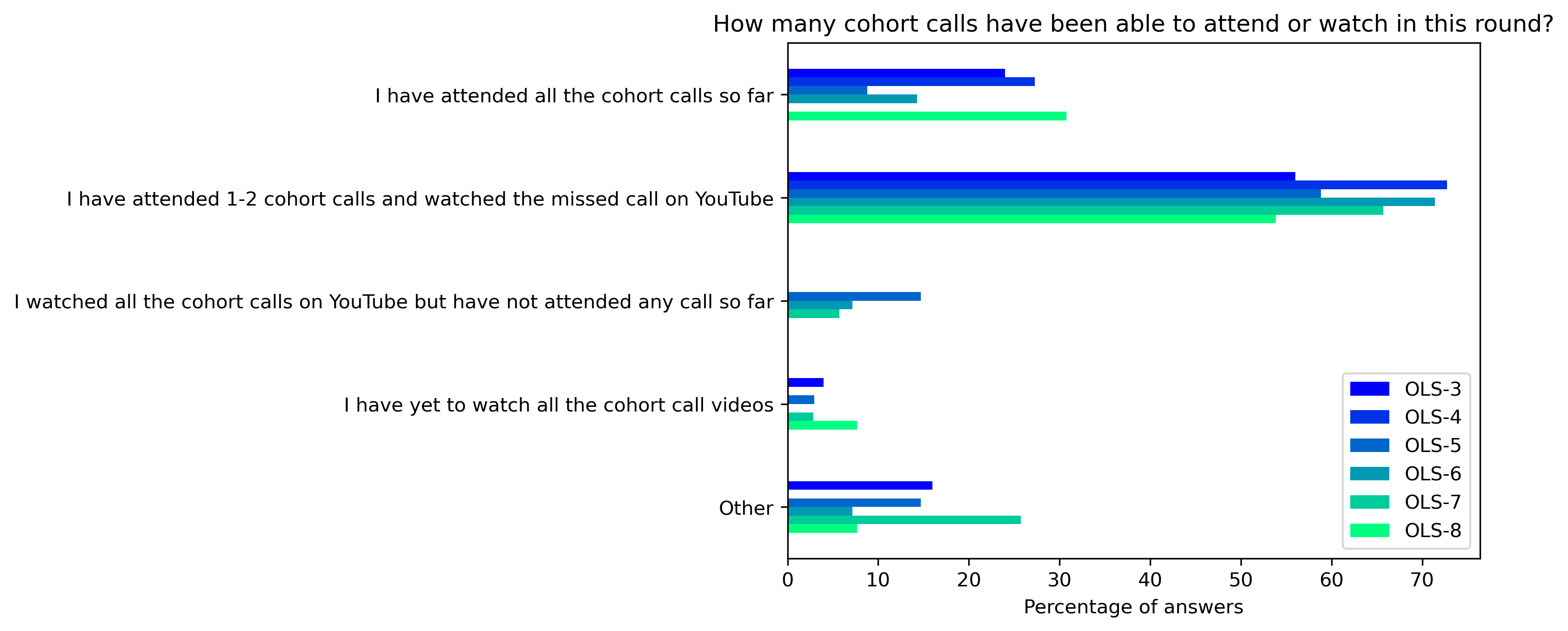
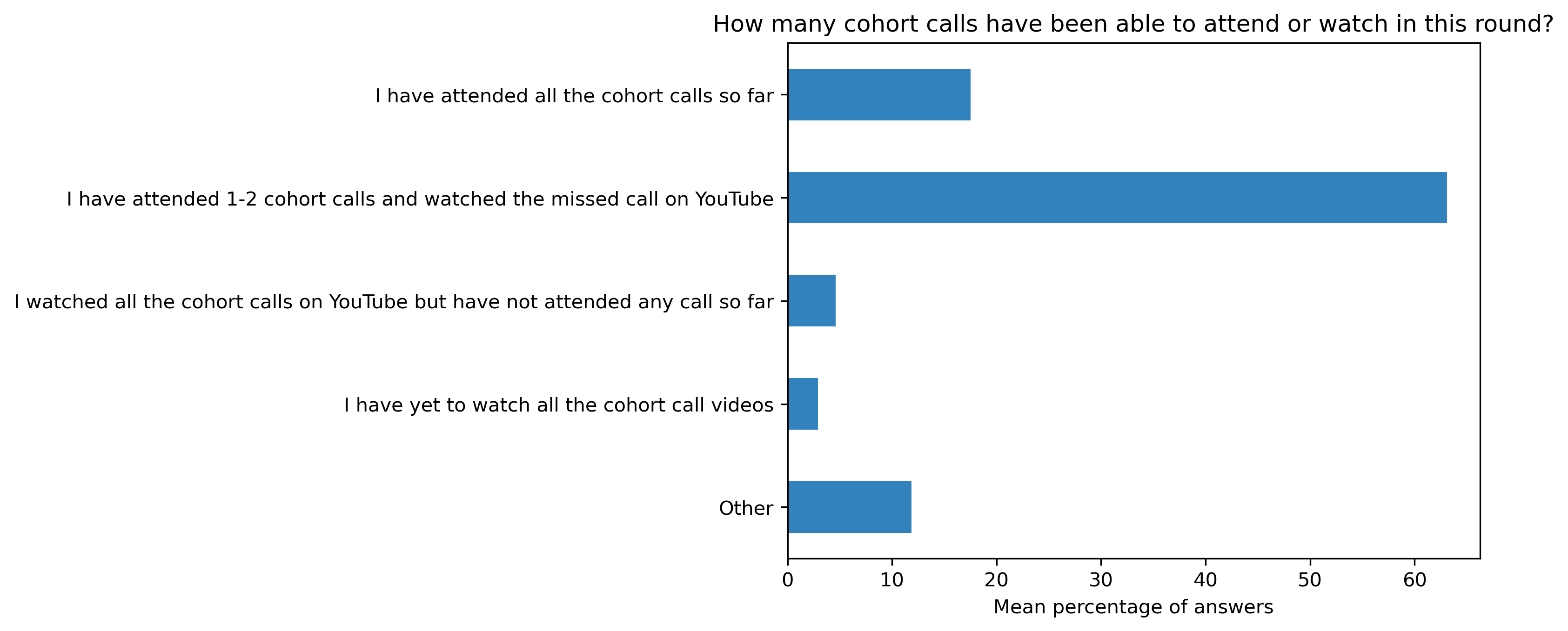
“How many cohort calls have been able to attend or watch in this round?”#
participant_mid_q8 = {}
other_answer = []
col = "How many cohort calls have been able to attend or watch in this round?"
answers = [
"I have attended all the cohort calls so far",
"I have attended 1-2 cohort calls and watched the missed call on YouTube",
"I watched all the cohort calls on YouTube but have not attended any call so far",
"I have yet to watch all the cohort call videos",
"Other"]
for c in participant_mid_df:
if col in participant_mid_df[c]:
participant_mid_q8[c], oa = get_mcq_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q8_df = pd.DataFrame.from_dict(participant_mid_q8)
participant_mid_q8_df = 100 * participant_mid_q8_df / participant_mid_q8_df.sum()
Other answers:
other_answer
['I have attended all the cohort calls except one',
'which I watched on YouTube',
'I have attended 4 cohort calls',
'and watched the missed call on YouTube',
'I have attended all except one',
'I have missed two cohort calls and watched the missed one on YouTube',
"I've been able to join most cohort calls",
'but have caught up on some missed sessions on YouTube.',
'I have attended all calls except one',
'3-4 cohort calls and the rest on Youtube',
'Attended 3 calls and watched the missed call on youtube. ',
'I have missed 2 cohort calls and watched the call on YouTube',
'i have attended most of the cohort calls ',
"I was not able to attend the first call or last week's call. ",
'I have attended 3 cohort calls',
'and watched the missed call on YouTube',
'I have attended more than 2 cohort calls',
'and watched some missed calls on YouTube but there are some of them that I have yet to watch',
'i have attended in most cohort calls and watched 2 on youtube ',
'Some']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q8_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
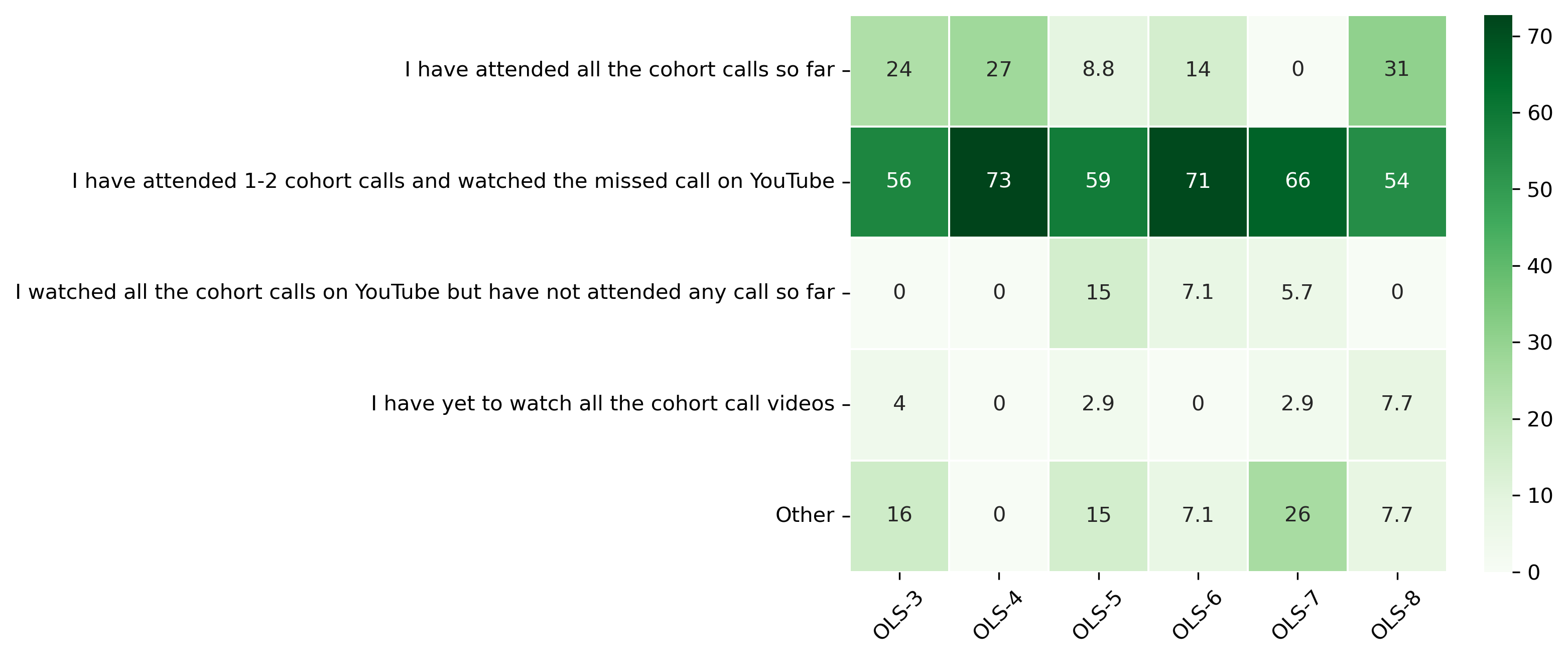
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q8_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q8_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
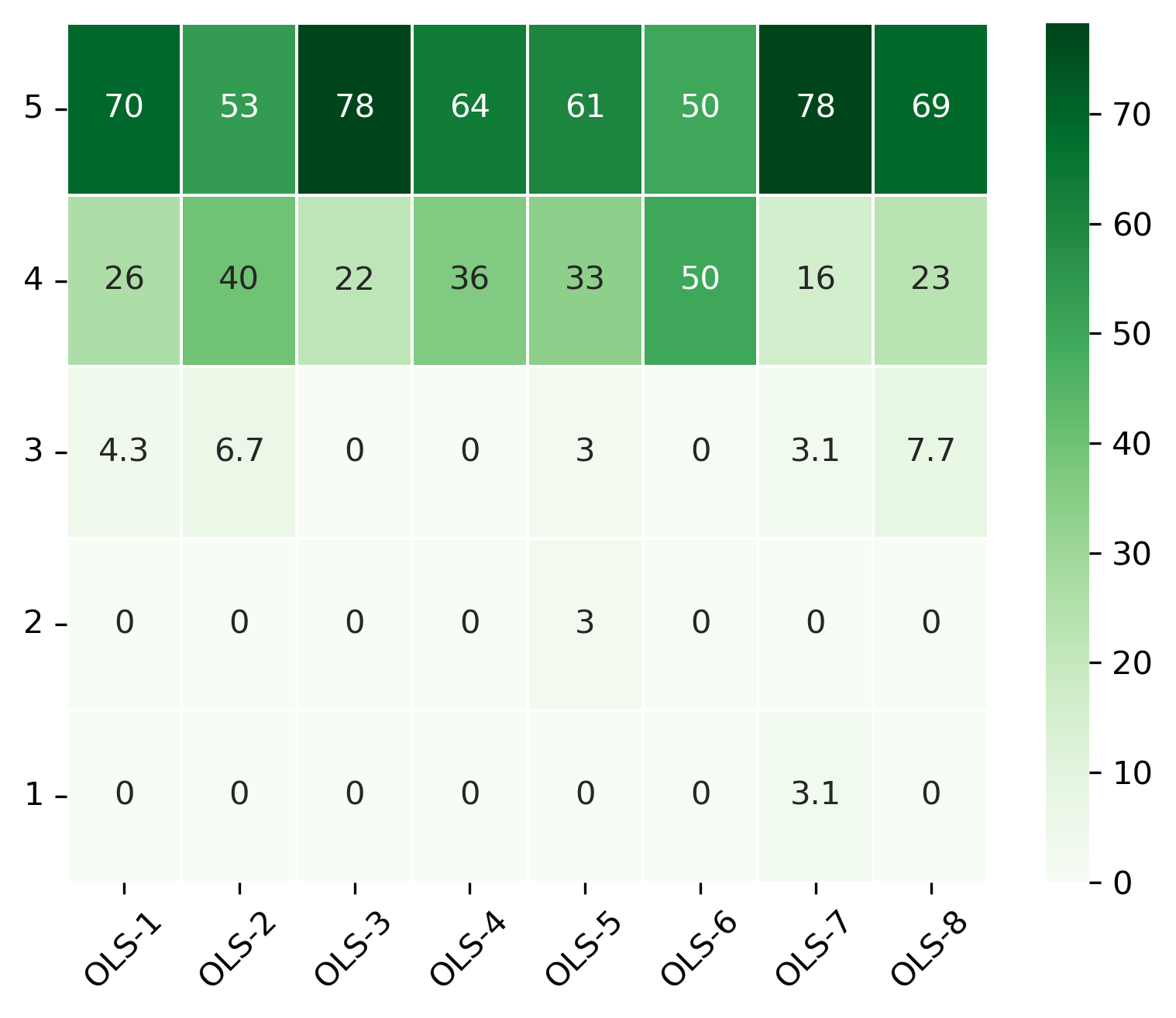
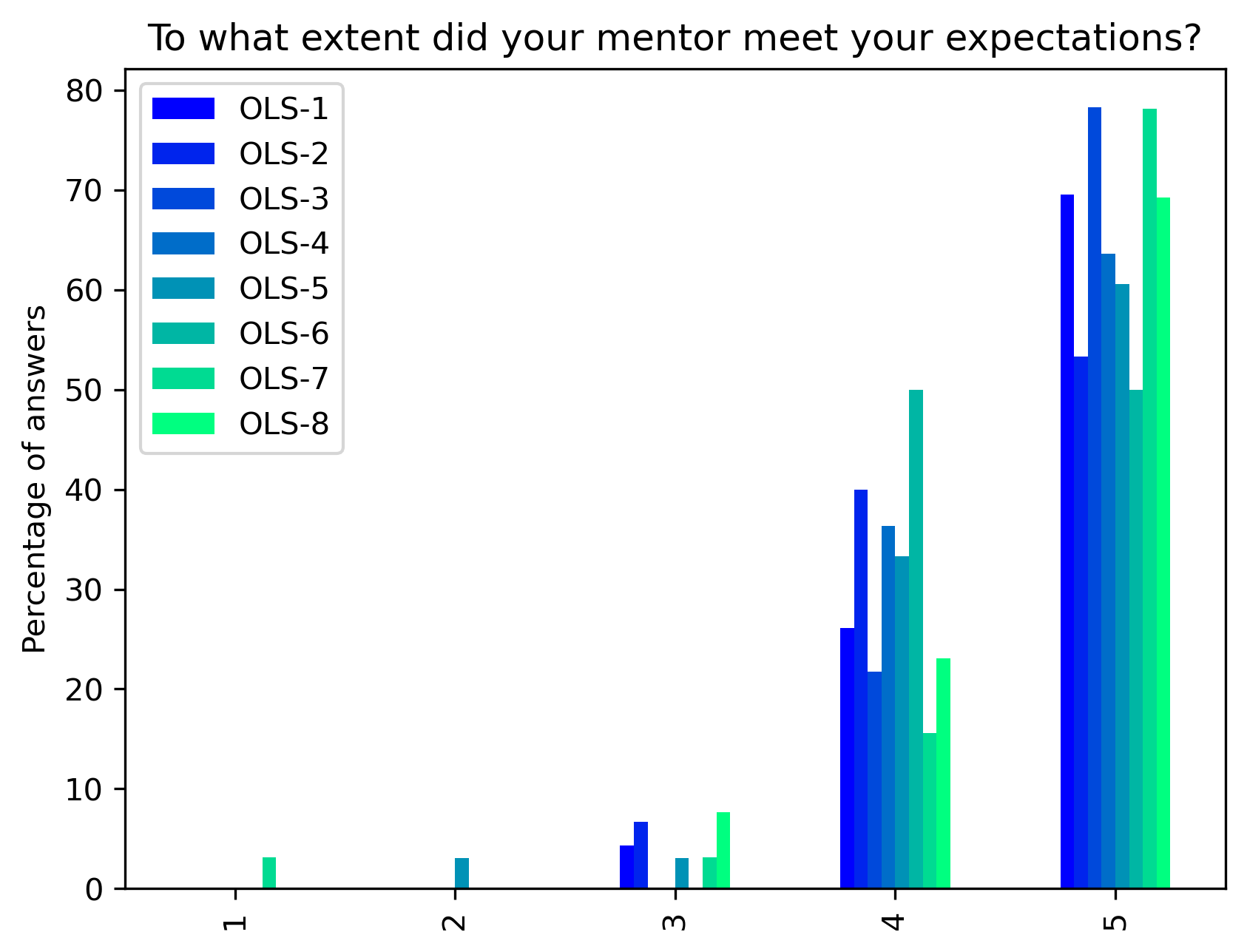
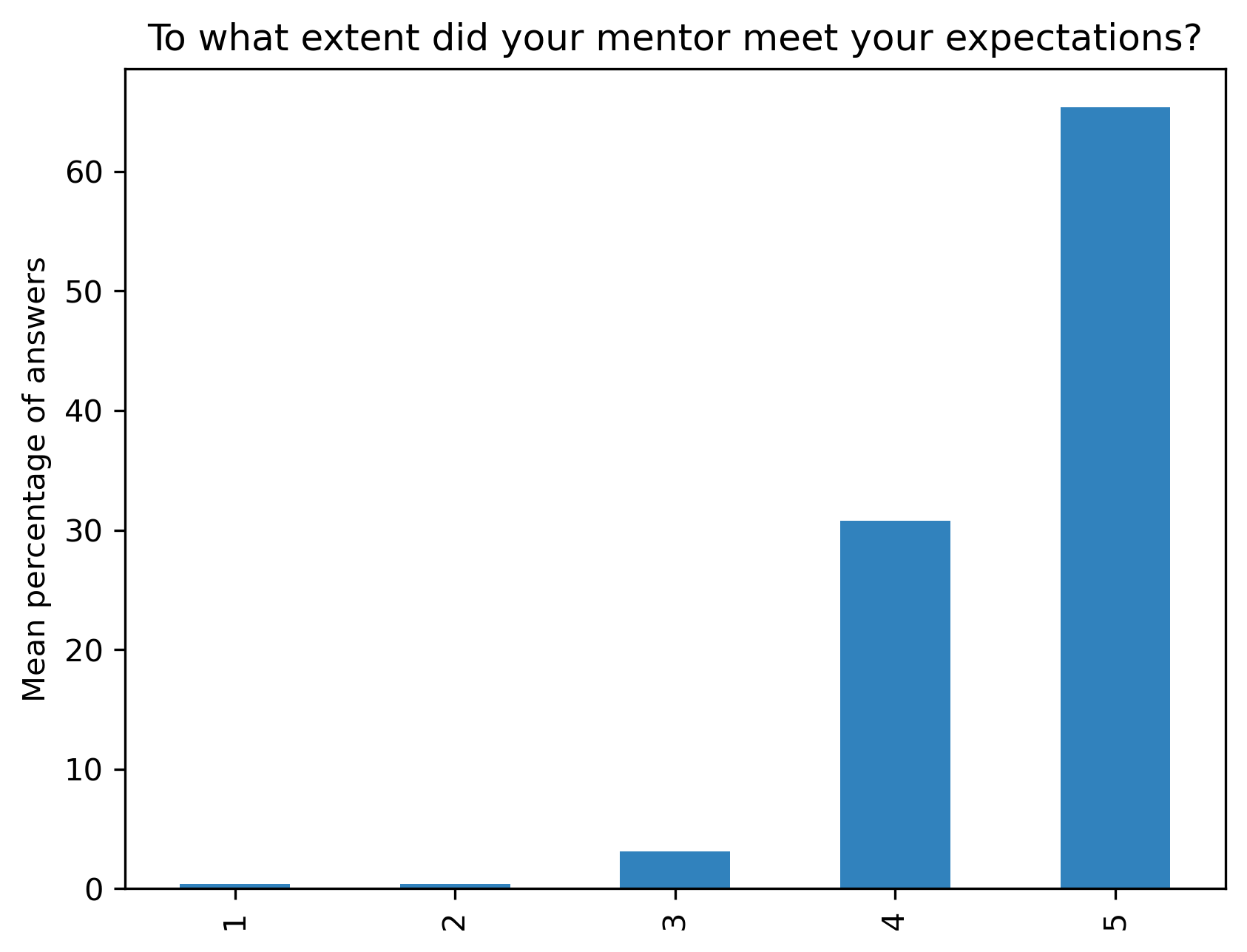
“To what extent did your mentor meet your expectations?”#
Range from 1 (Not at all) to 5 (Completely)
participant_mid_q9 = {}
other_answer = []
col = "To what extent did your mentor meet your expectations?"
answers = list(range(1, 6))
for c in participant_mid_df:
participant_mid_q9[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q9_df = pd.DataFrame.from_dict(participant_mid_q9)
participant_mid_q9_df = 100 * participant_mid_q9_df / participant_mid_q9_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q9_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q9_df.plot.bar(ax=ax, colormap=colors['participant_colormap'])
plt.ylabel('Percentage of answers')
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q9_df.mean(axis=1).plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Mean percentage of answers')
t = plt.title(col)
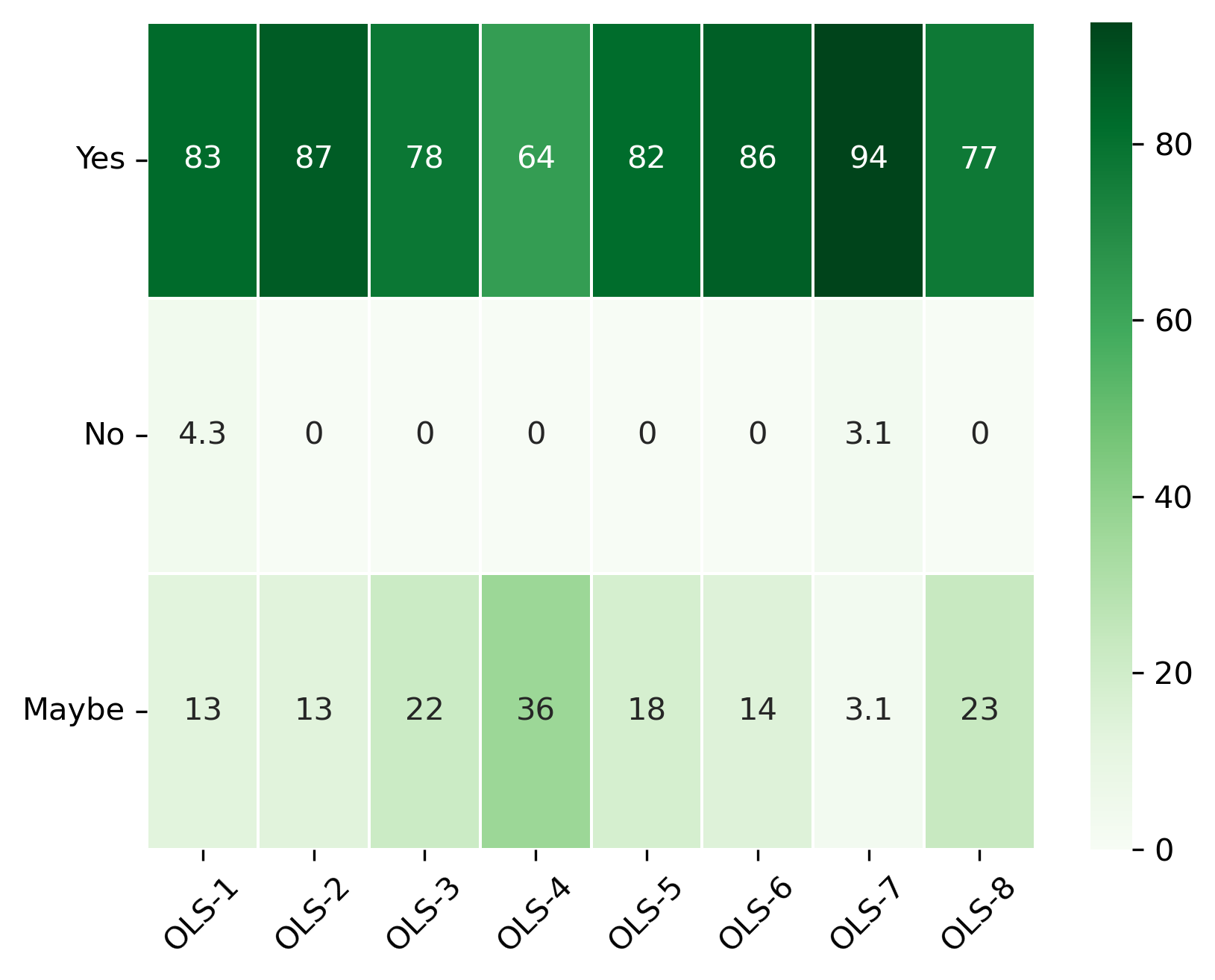
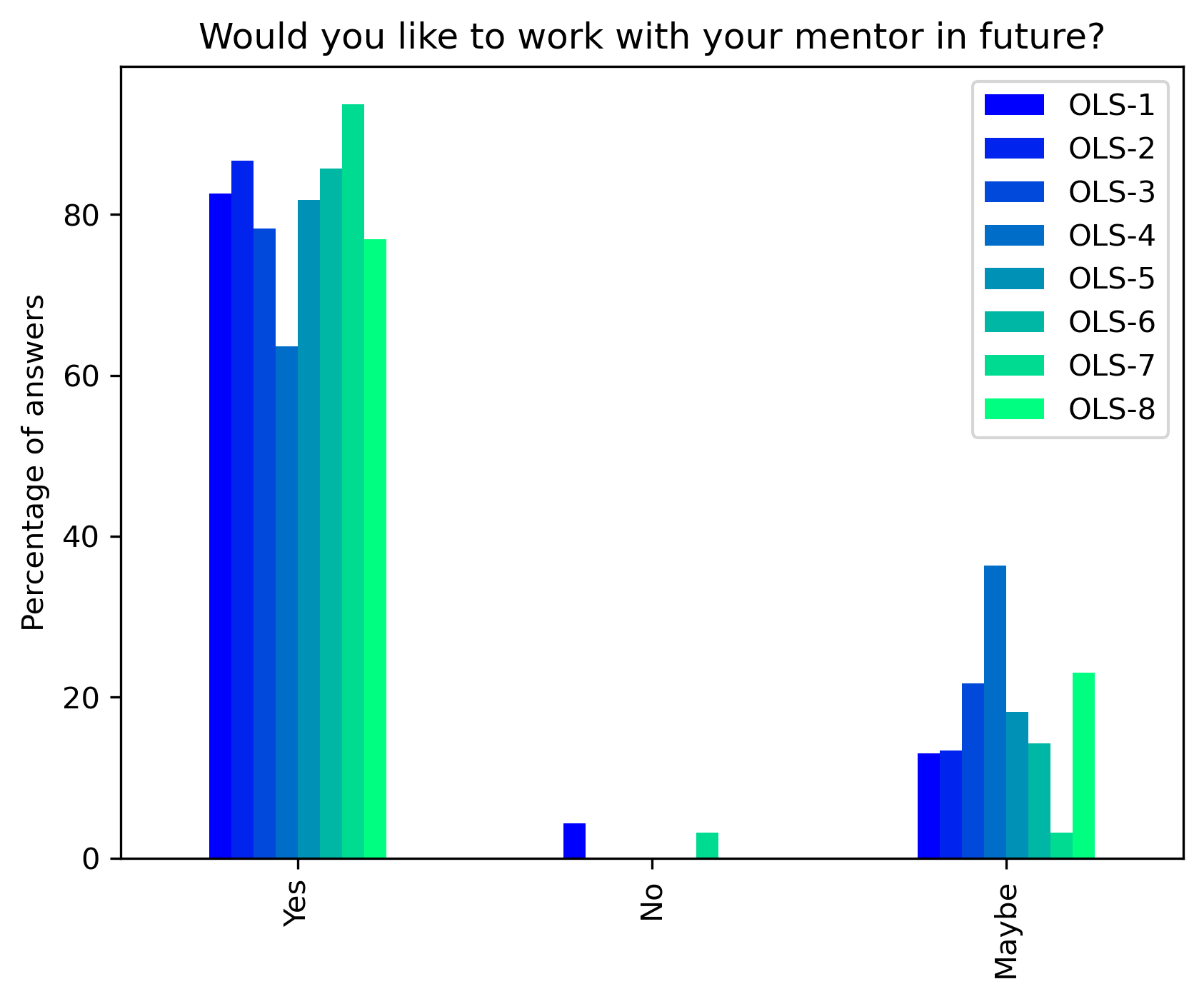
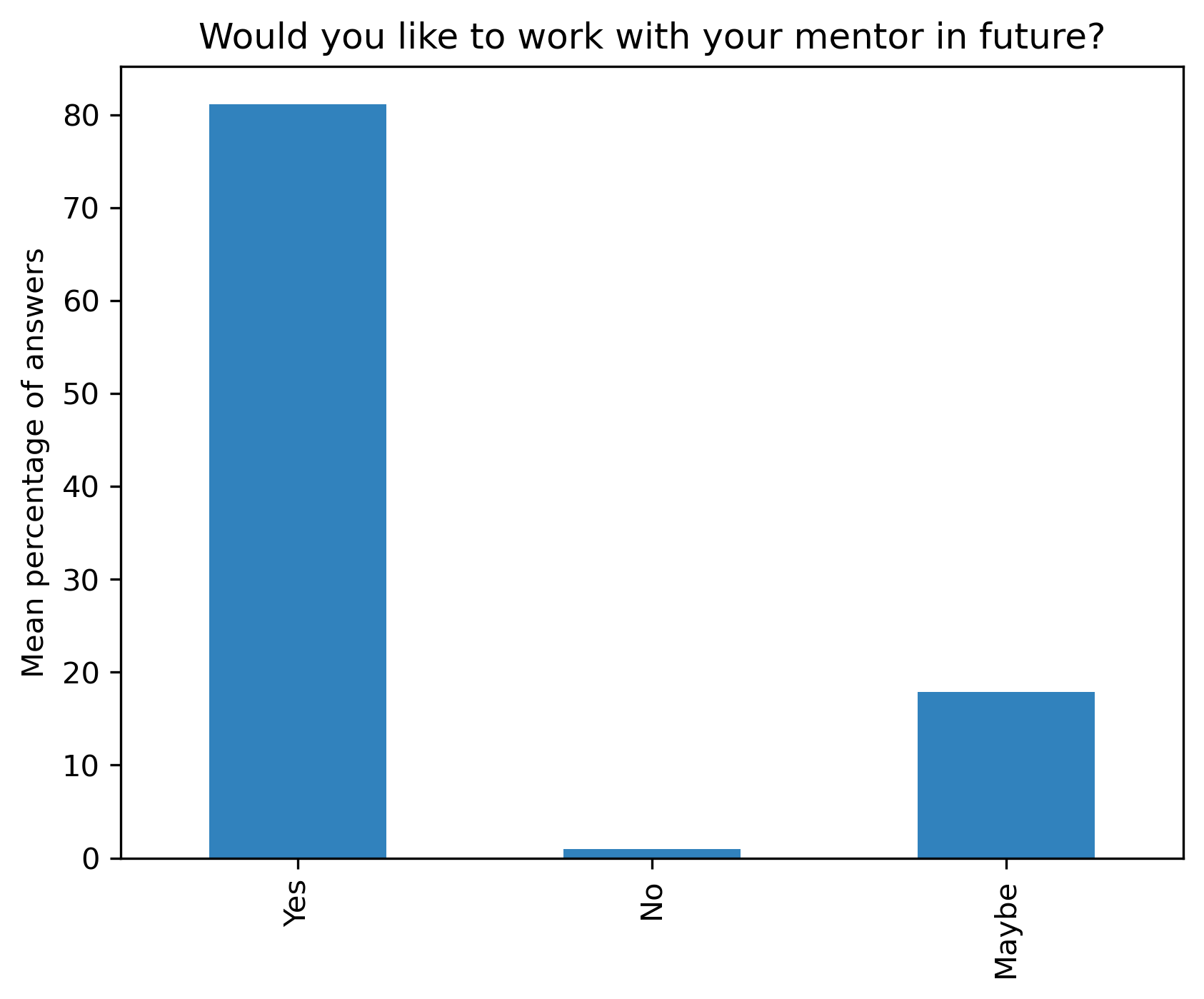
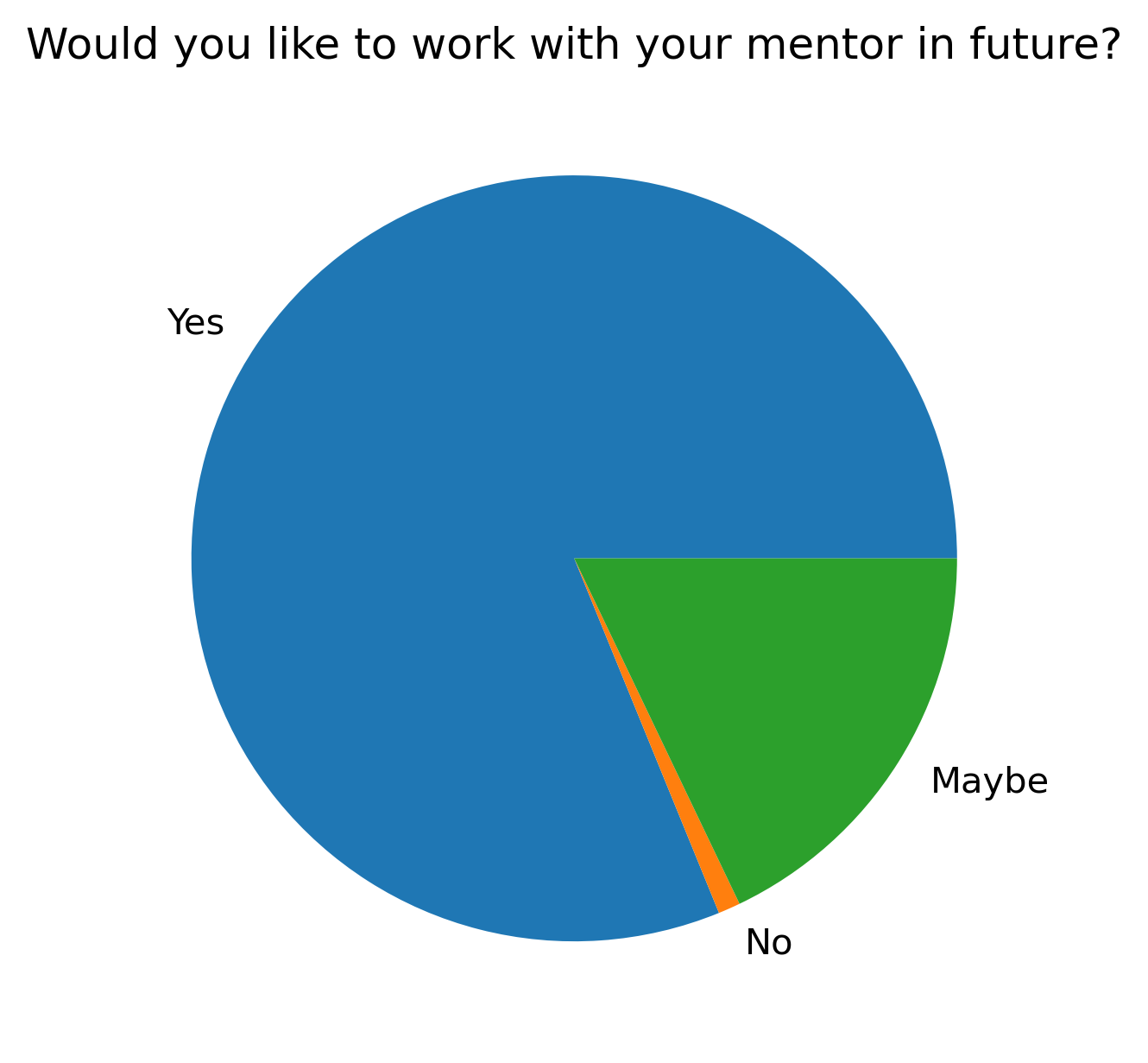
“Would you like to work with your mentor in future?”#
participant_mid_q10 = {}
other_answer = []
col = "Would you like to work with your mentor in future?"
answers = ["Yes", "No", "Maybe"]
for c in participant_mid_df:
participant_mid_q10[c], oa = get_question_possible_answers_counts(col, participant_mid_df[c], answers)
other_answer += oa
participant_mid_q10_df = pd.DataFrame.from_dict(participant_mid_q10)
participant_mid_q10_df = 100 * participant_mid_q10_df / participant_mid_q10_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_mid_q10_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q10_df.plot.bar(ax=ax, colormap=colors['participant_colormap'])
plt.ylabel('Percentage of answers')
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q10_df.mean(axis=1).plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Mean percentage of answers')
t = plt.title(col)
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_mid_q10_df.mean(axis=1).plot.pie()
t = plt.title(col)
Post-cohort#
Participants#
url = "https://docs.google.com/spreadsheets/d/1TlJ8_m1G4vLz0FH_IEgTGqjeQNvH8IYk0RM3wzaYanQ/export?format=csv"
cohort_gid = {
'OLS-1': '1016086495',
'OLS-2': '1605575560',
'OLS-3': '1197781372',
'OLS-4': '992604217',
'OLS-5': '0',
'OLS-6': '1071501789',
'OLS-7': '792445015'
}
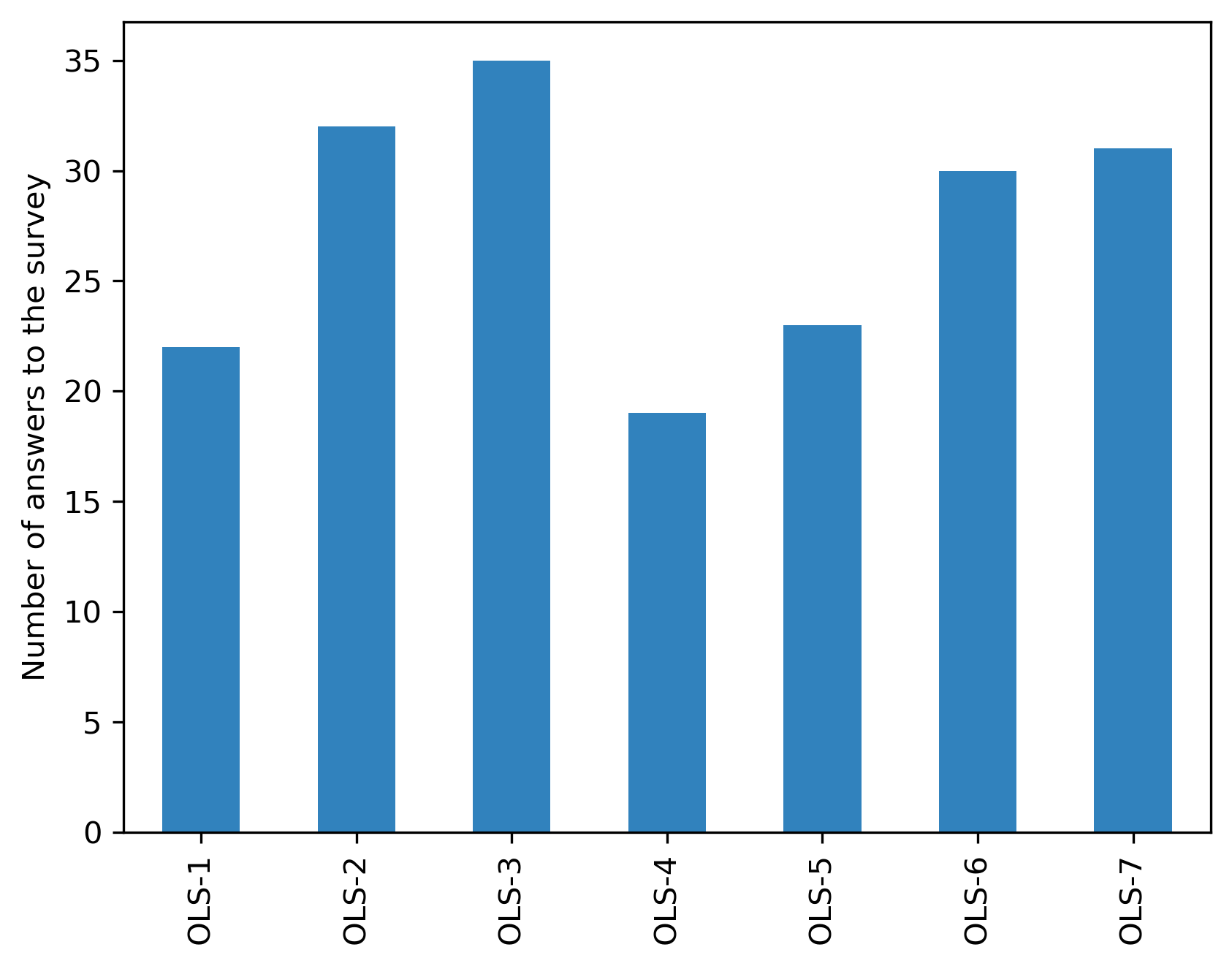
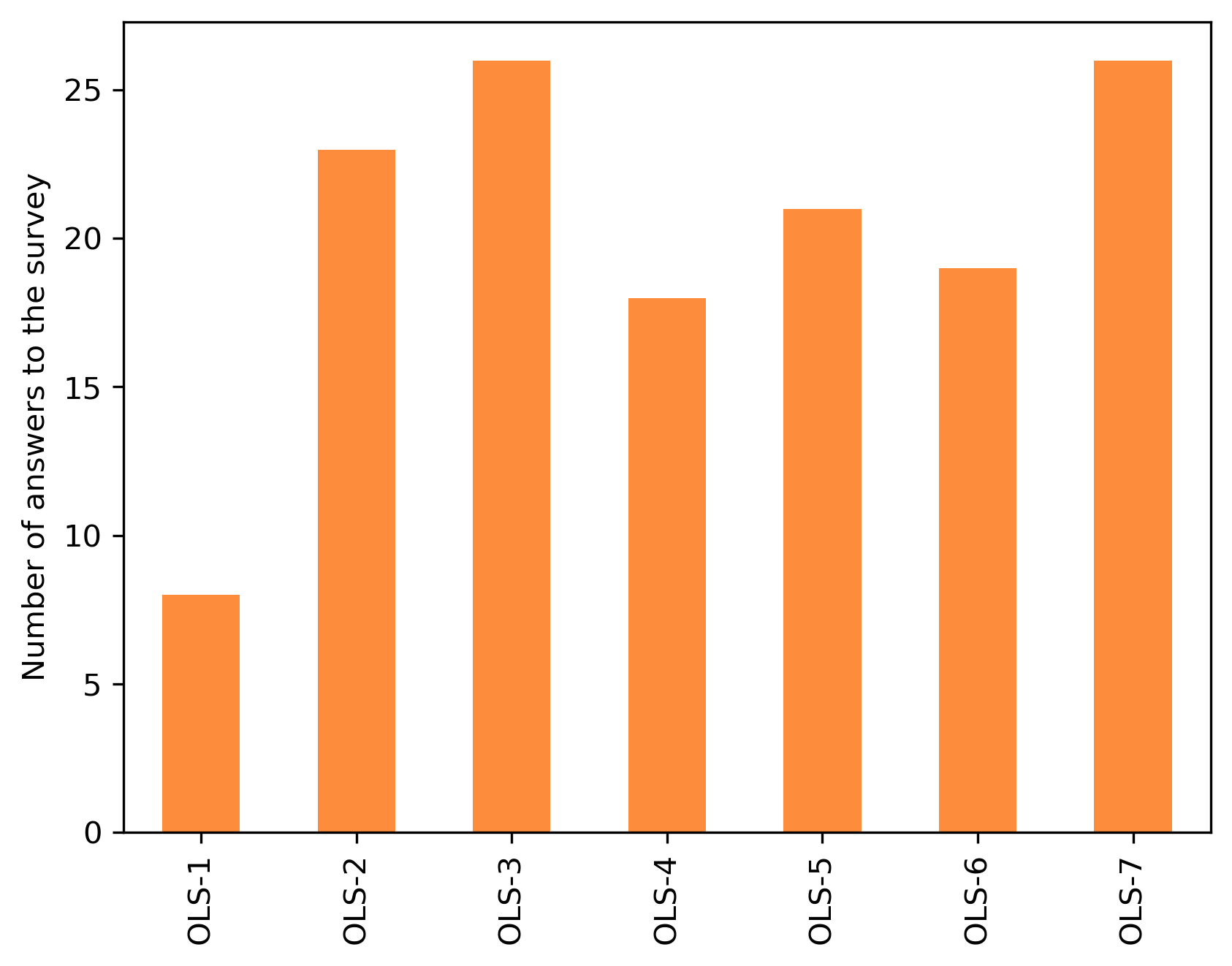
participant_df = {}
answers = {}
for c in cohort_gid:
participant_df[c] = (
pd.read_csv(f"{url}&gid={cohort_gid[c]}")
.dropna(axis=1,how='all')
.fillna("")
.replace(c, "cohort", regex=True)
# q1
.replace("I was able to meet ALL my project goals", "I was able to meet ALL my goals", regex=True)
.replace("I worked consistently on my project, and met part of my goals", "I was able to meet MOST of my goals", regex=True)
.replace("I was able to meet MOST of my goals.", "I was able to meet MOST of my goals", regex=True)
# q4
## renaming (see below)
.replace("Tooling and Roadmapping \(open canvas, project vision etc\.\)", "Project Roadmapping, Open Canvas", regex=True)
.replace("Licensing and Code of Conduct", "Open Licensing, Code of Conduct", regex=True)
.replace("GitHub and README files", "README, GitHub Introduction", regex=True)
.replace("Project development: Agile and iterative project management methods & Open Aspects", "Agile & Iteractive Project Management", regex=True)
.replace("Knowledge Dissemination: Preprints, Training and Code Publishing", "Open Access Publication, Open Educational Resources, Open Source Software", regex=True)
.replace("Data management plans, software citation", "Open Data", regex=True)
.replace("Citizen Science", "Open Engagement of Social Actors", regex=True)
.replace("citizen science", "Open Engagement of Social Actors", regex=True)
.replace("Diversity & Inclusion", "Equity Diversity & Inclusion (EDI)", regex=True)
.replace("Mountain of engagement and Community interactions", "Mountain of Engagement, Community Interactions", regex=True)
.replace("Persona and pathways and inviting contributions", "Personas & Pathways", regex=True)
.replace("Mental health, self care, personal ecology", "Personal Ecology", regex=True)
.replace("Ally skills", "Ally Skills for Open Leaders", regex=True)
.replace("Open Leadership: Career Guidance call", "Open Leadership in Practice", regex=True)
.replace("Open office/co-working hours and social calls", "Open office/co-working hours and social calls", regex=True)
.replace("Final presentation rehearsals", "Graduation rehearsals", regex=True)
.replace("Final presentation call \(open and live streamed\)", "Graduations", regex=True)
## cleaning
.replace("Tooling and Roadmapping \(\)", "Project Roadmapping, Open Canvas", regex=True)
#.replace("Tooling and Roadmapping(open canvas, project vision etc.)", "Project Roadmapping, Open Canvas", regex=True)
.replace("Designing for inclusion: Implicit bias", "Community Design for Inclusivity", regex=True)
.replace("Diversity and Inclusion", "Equity Diversity & Inclusion (EDI)", regex=True)
.replace("Preprints", "Open Access Publication", regex=True)
.replace("open protocols", "Open Evaluation", regex=True)
.replace("Knowledge Dissemination: Citizen science", "Open Engagement of Social Actors", regex=True)
.replace("Knowledge Dissemination: open education", "Open Educational Resources", regex=True)
.replace("Knowledge Dissemination: Open Access Publication", "Open Access Publication", regex=True)
.replace("open education", "Open Educational Resources", regex=True)
.replace("Open agenda and social calls", "Open office/co-working hours and social calls", regex=True)
.replace("Career Guidance calls", "Open Leadership in Practice", regex=True)
.replace("Applying FAIR principles on research components", "Open Data", regex=True)
# q5
.replace("I am not sure yet, but ask me later when you have launched OLS-2", "I am not sure yet but ask me later", regex=True)
.replace("I am not sure yet, but ask me later when you have launched cohort", "I am not sure yet but ask me later", regex=True)
.replace("I am not sure yet, but ask me later", "I am not sure yet but ask me later", regex=True)
.replace("Yes I'd like to return as a collaborator to run an OLS cohort for my network", "Yes I'd like to return as a collaborator to run this program in my network", regex=True)
.replace("No, I would not be able to return to OLS-2", "No I would not be able to return", regex=True)
.replace("No, I would not be able to return to cohort", "No I would not be able to return", regex=True)
.replace("No, I would not be able to return to OLS-4", "No I would not be able to return", regex=True)
.replace("I would not be able to return to OLS-3 but I am hopeful to return to OLS-4 with an active role.", "I would take a break but please keep me informed about the next cohort", regex=True)
.replace("No, but only because I really would not have the time", "No I would not be able to return", regex=True)
.replace("Maybe in OLS-7?", "I would take a break but please keep me informed about the next cohort", regex=True)
)
answers[c] = participant_df[c].shape[0]
<>:15: SyntaxWarning: invalid escape sequence '\('
<>:31: SyntaxWarning: invalid escape sequence '\('
<>:33: SyntaxWarning: invalid escape sequence '\('
<>:15: SyntaxWarning: invalid escape sequence '\('
<>:31: SyntaxWarning: invalid escape sequence '\('
<>:33: SyntaxWarning: invalid escape sequence '\('
/tmp/ipykernel_2105/2932574586.py:15: SyntaxWarning: invalid escape sequence '\('
.replace("Tooling and Roadmapping \(open canvas, project vision etc\.\)", "Project Roadmapping, Open Canvas", regex=True)
/tmp/ipykernel_2105/2932574586.py:31: SyntaxWarning: invalid escape sequence '\('
.replace("Final presentation call \(open and live streamed\)", "Graduations", regex=True)
/tmp/ipykernel_2105/2932574586.py:33: SyntaxWarning: invalid escape sequence '\('
.replace("Tooling and Roadmapping \(\)", "Project Roadmapping, Open Canvas", regex=True)
answer_s = pd.Series(answers)
answer_s
fig, ax = plt.subplots()
fig.set_dpi(300)
answer_s.plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Number of answers to the survey')
Text(0, 0.5, 'Number of answers to the survey')
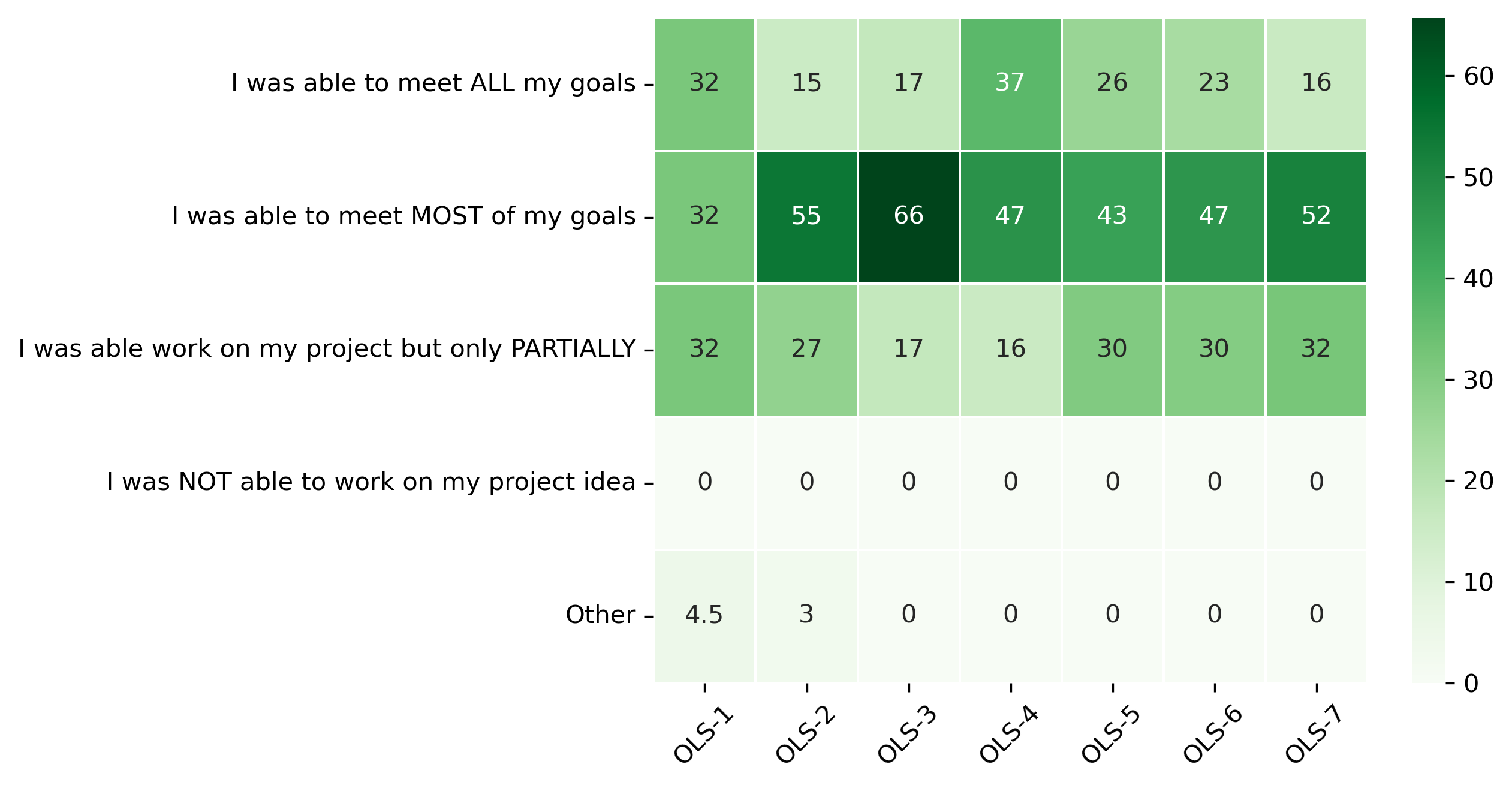
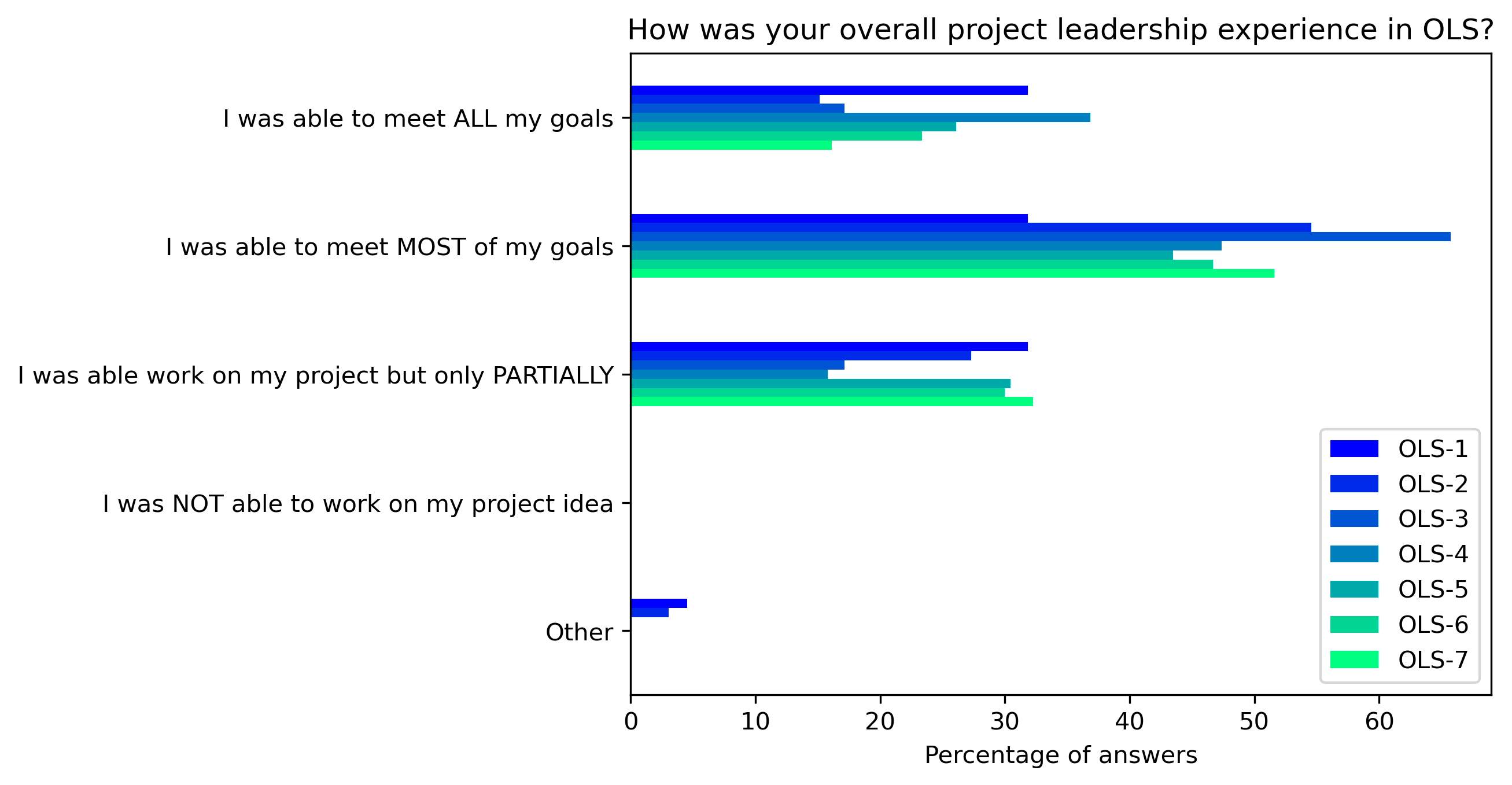
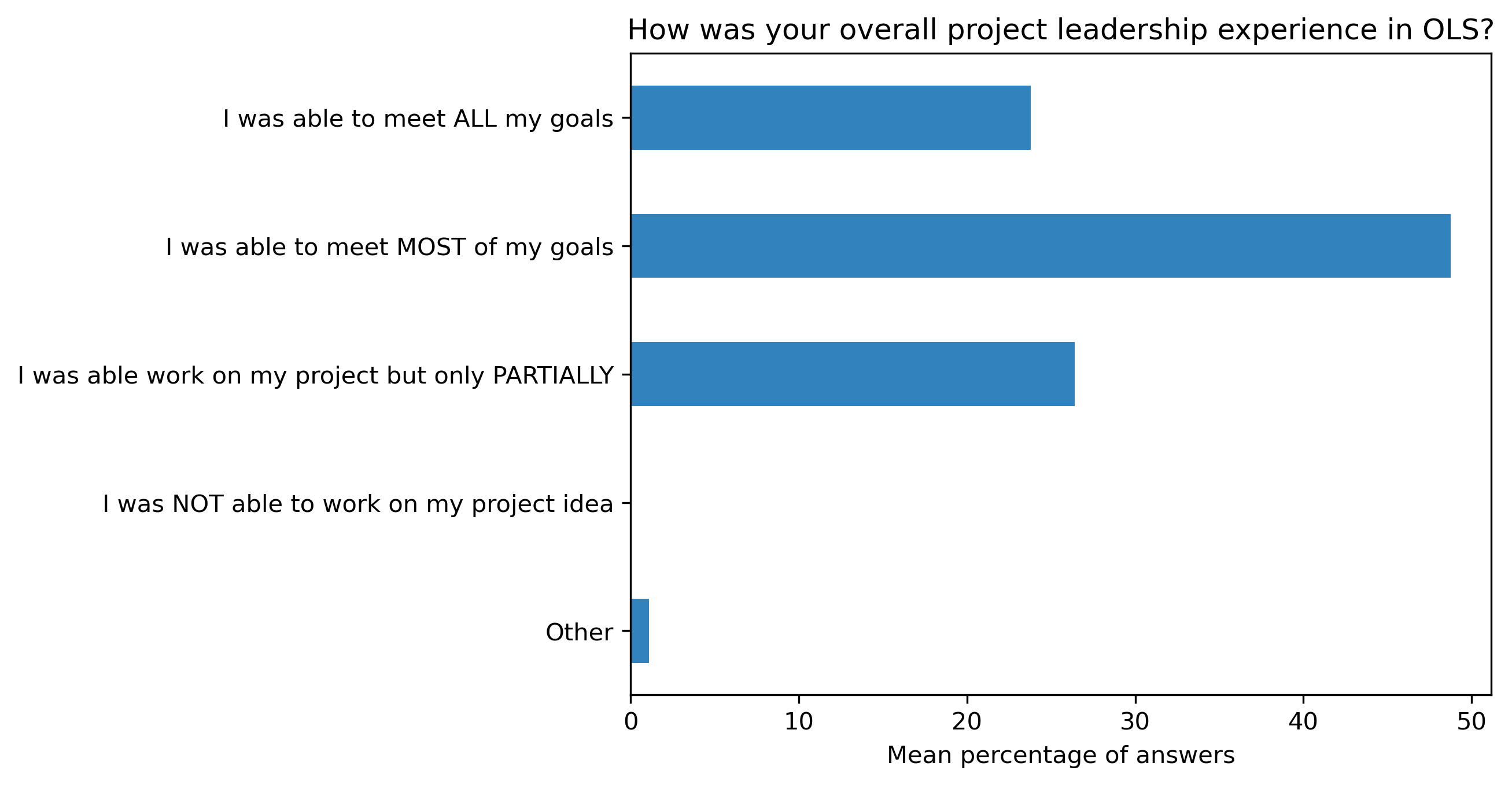
“How was your overall project leadership experience in OLS?”#
participant_q1 = {}
other_answer = []
col = "How was your overall project leadership experience in OLS?"
answers = [
"I was able to meet ALL my goals",
"I was able to meet MOST of my goals",
"I was able work on my project but only PARTIALLY",
"I was NOT able to work on my project idea",
"Other"]
for c in participant_df:
participant_q1[c], oa = get_mcq_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q1_df = pd.DataFrame.from_dict(participant_q1)
participant_q1_df = 100 * participant_q1_df / participant_q1_df.sum()
Other answers:
other_answer
['Goals evolved as we learned but we were very productive ',
"I had some personal goals which were not completed - but that's fine :)"]
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q1_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q1_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q1_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
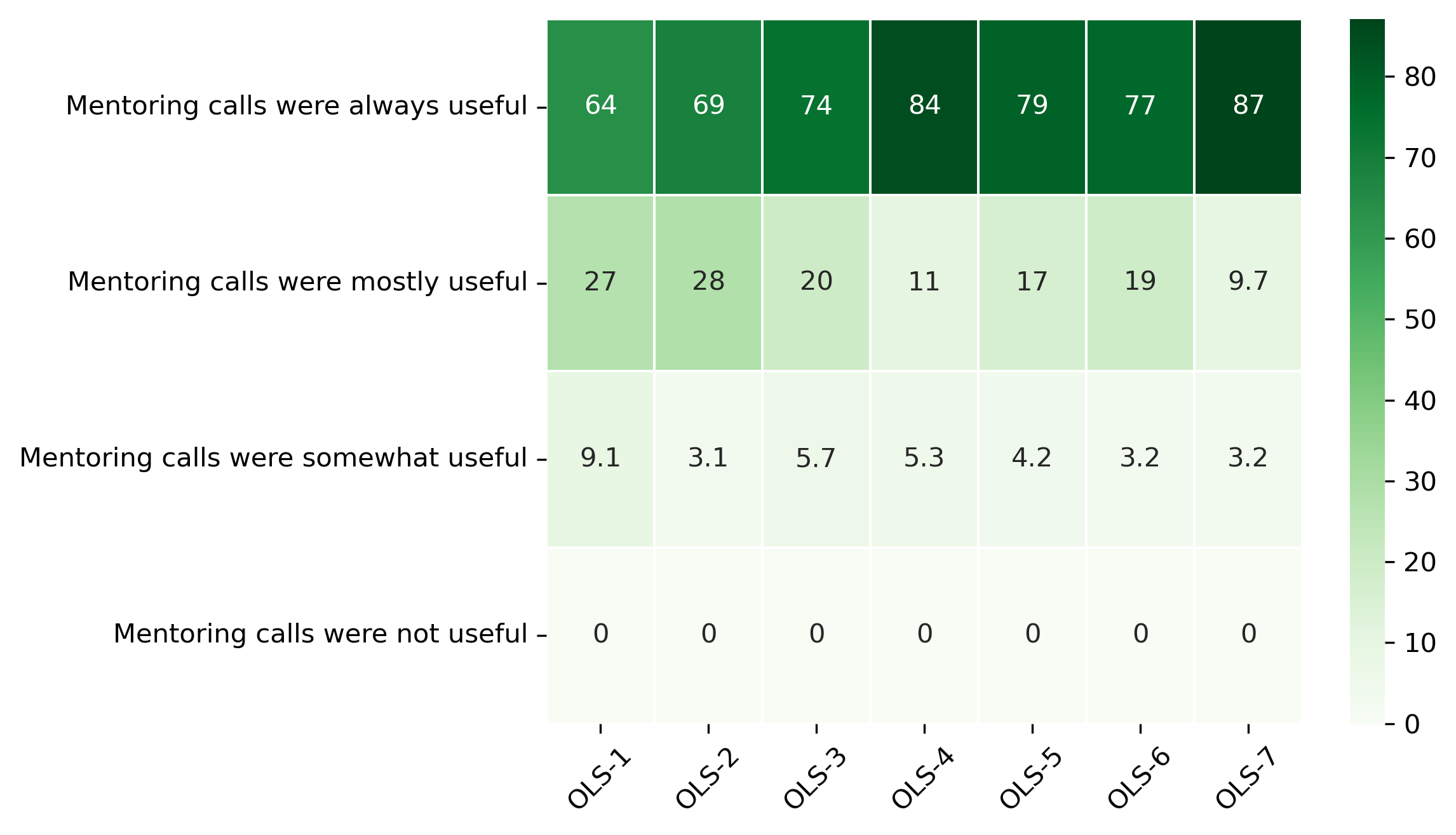
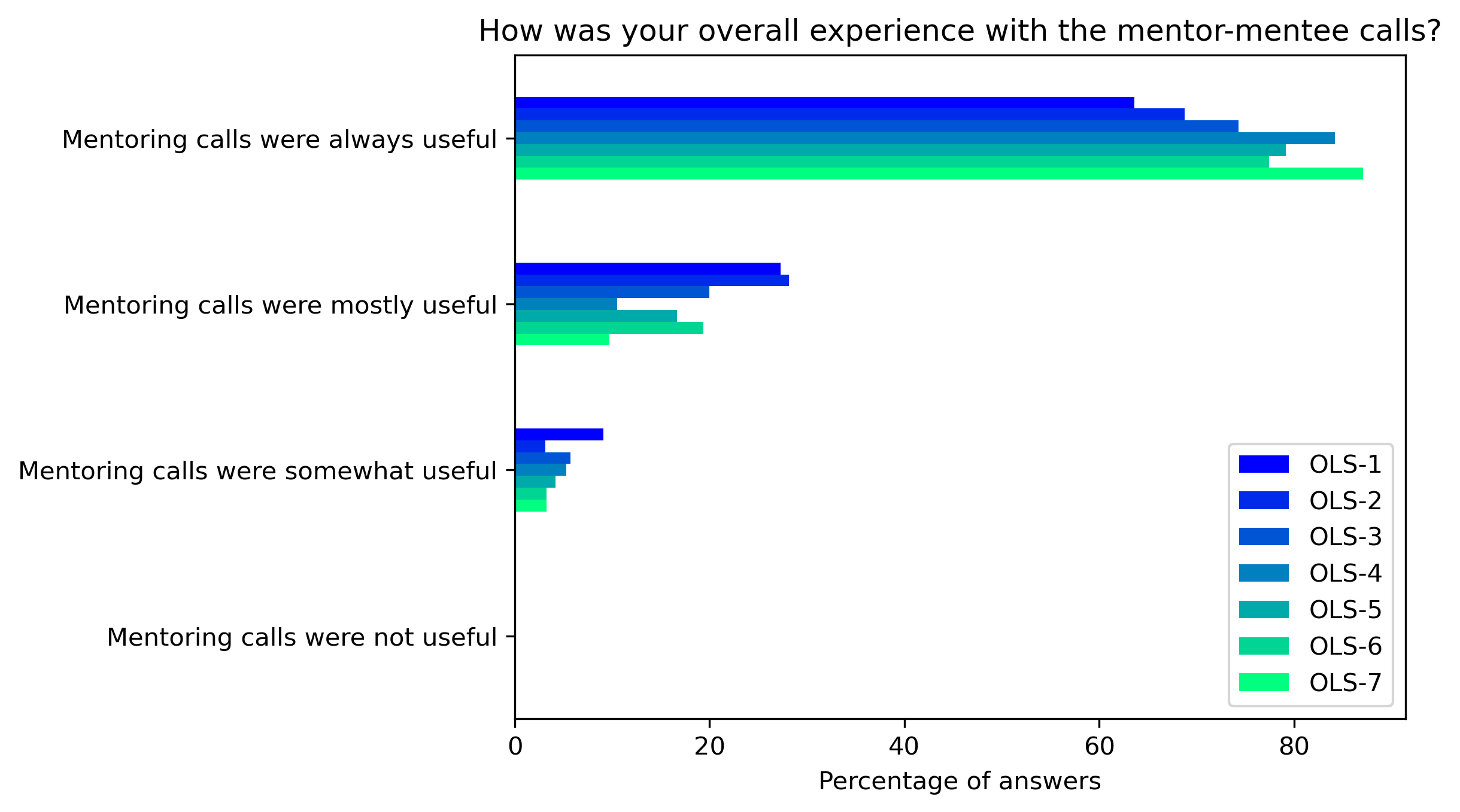
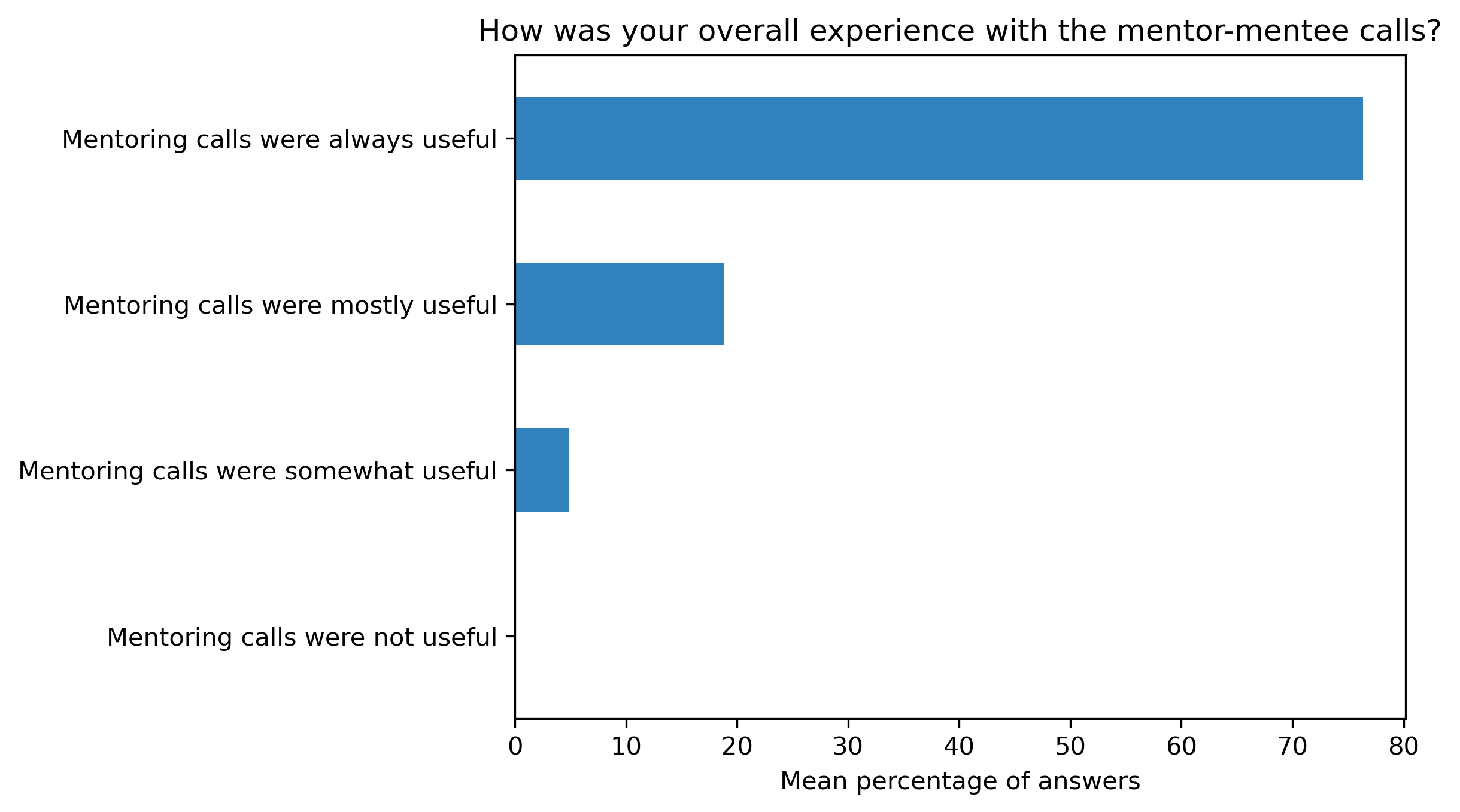
“How was your overall experience with the mentor-mentee calls?”#
participant_q2 = {}
other_answer = []
col = "How was your overall experience with the mentor-mentee calls?"
answers = [
"Mentoring calls were always useful",
"Mentoring calls were mostly useful",
"Mentoring calls were somewhat useful",
"Mentoring calls were not useful"]
for c in participant_df:
participant_q2[c], oa = get_mcq_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q2_df = pd.DataFrame.from_dict(participant_q2)
participant_q2_df = 100 * participant_q2_df / participant_q2_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q2_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q2_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q2_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
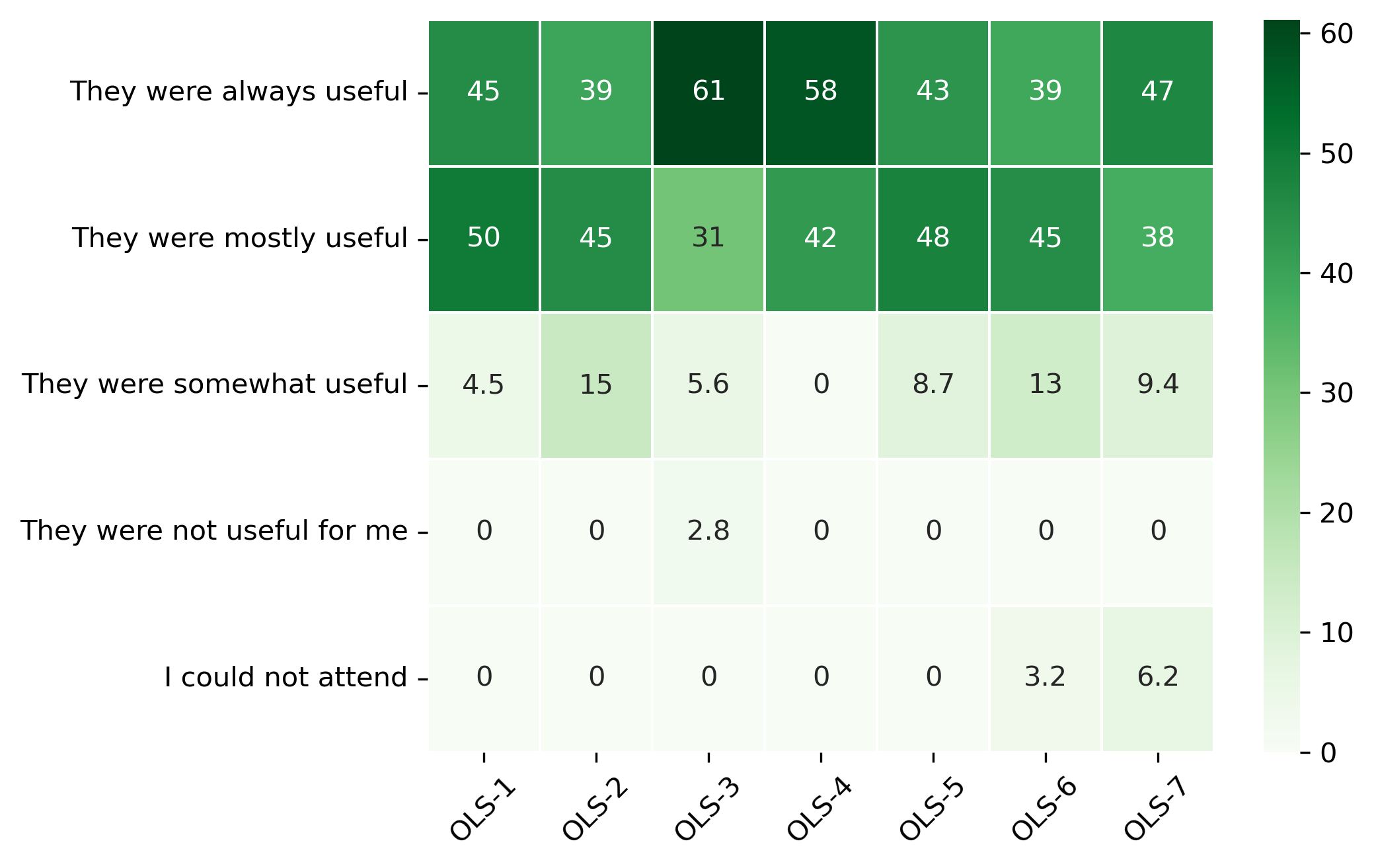
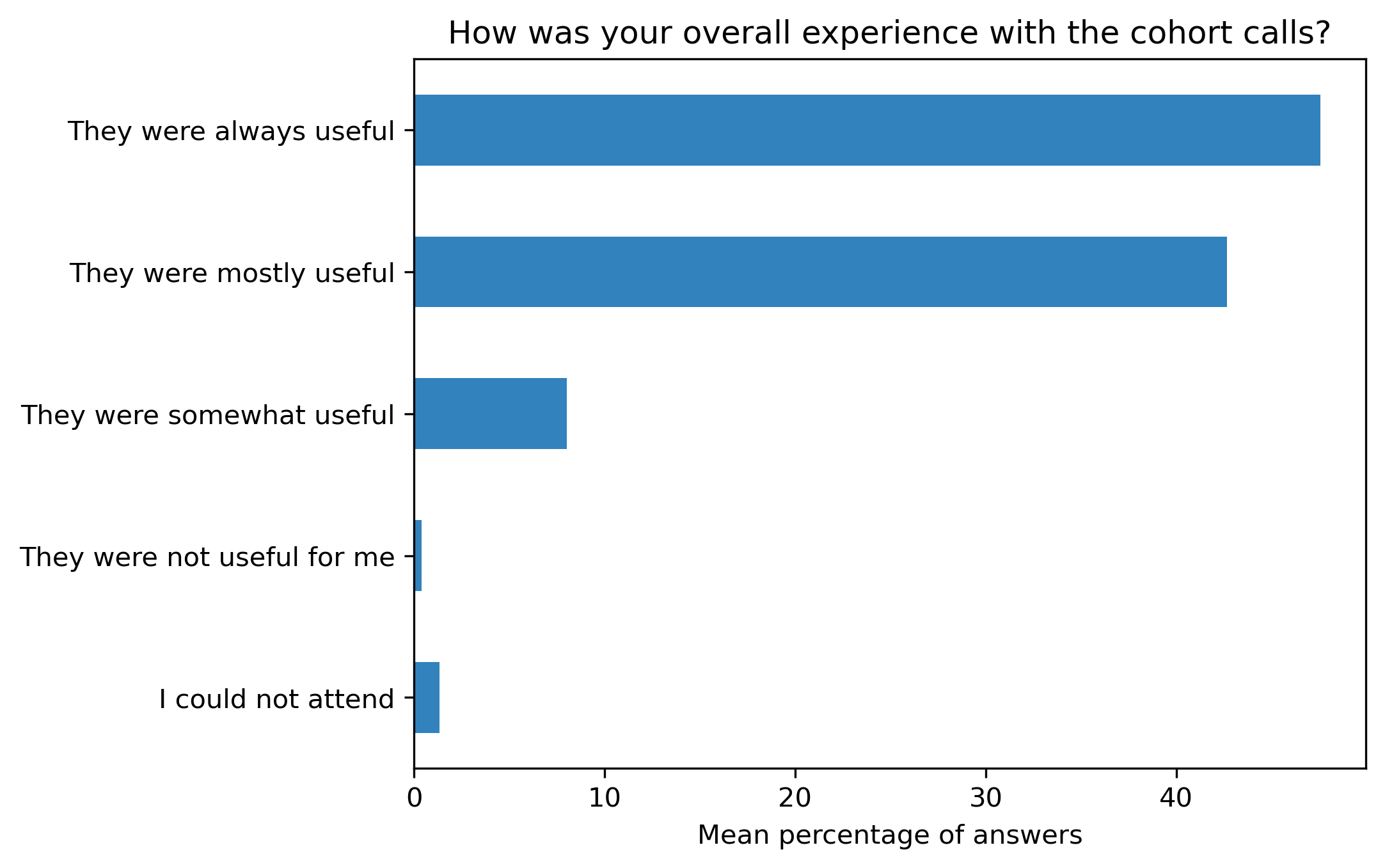
“How was your overall experience with the cohort calls?”#
participant_q3 = {}
other_answer = []
col = "How was your overall experience with the cohort calls?"
answers = [
"They were always useful",
"They were mostly useful",
"They were somewhat useful",
"They were not useful for me",
"I could not attend"]
for c in participant_df:
participant_q3[c], oa = get_mcq_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q3_df = pd.DataFrame.from_dict(participant_q3)
participant_q3_df = 100 * participant_q3_df / participant_q3_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q3_df, cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q3_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
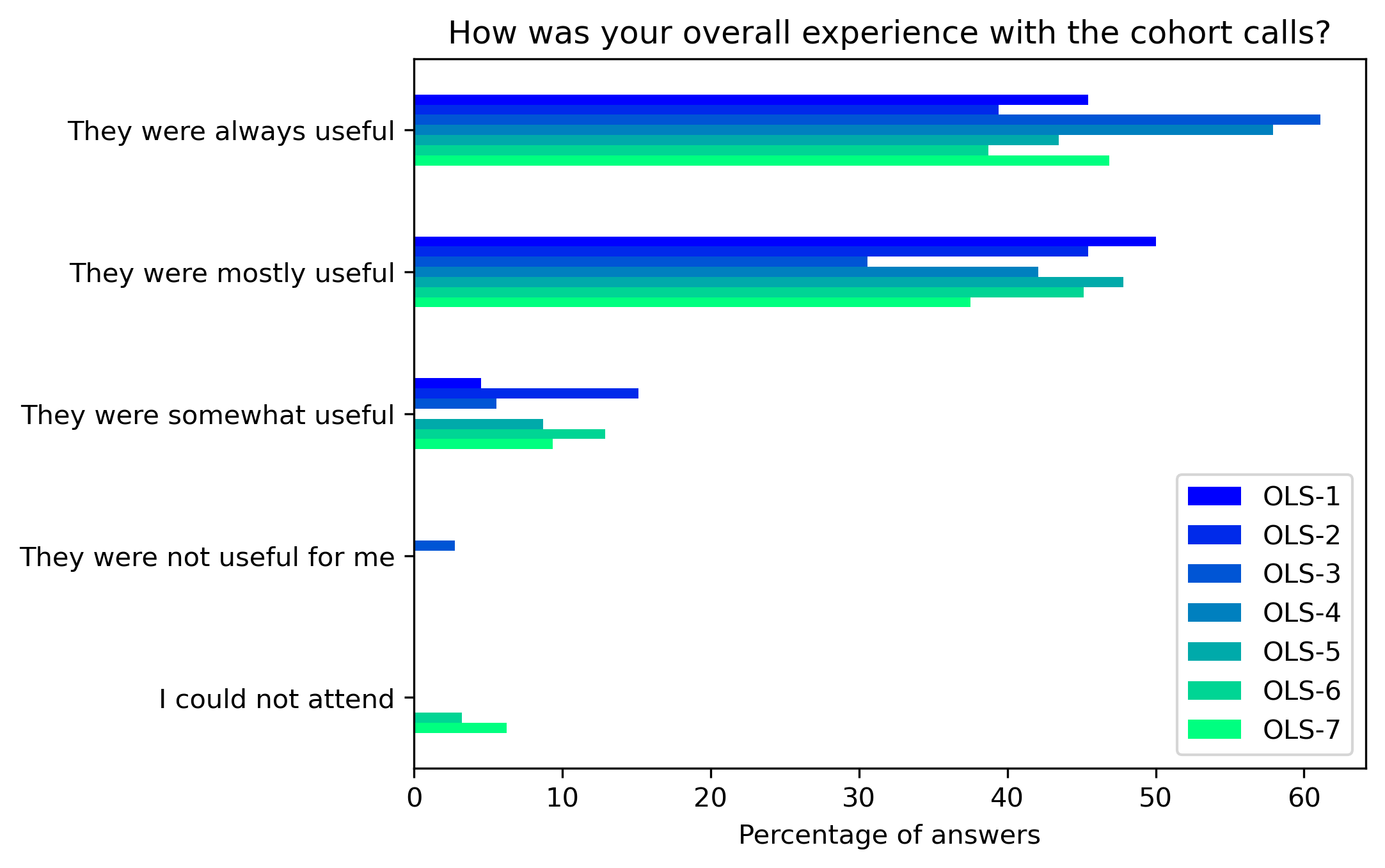
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q3_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
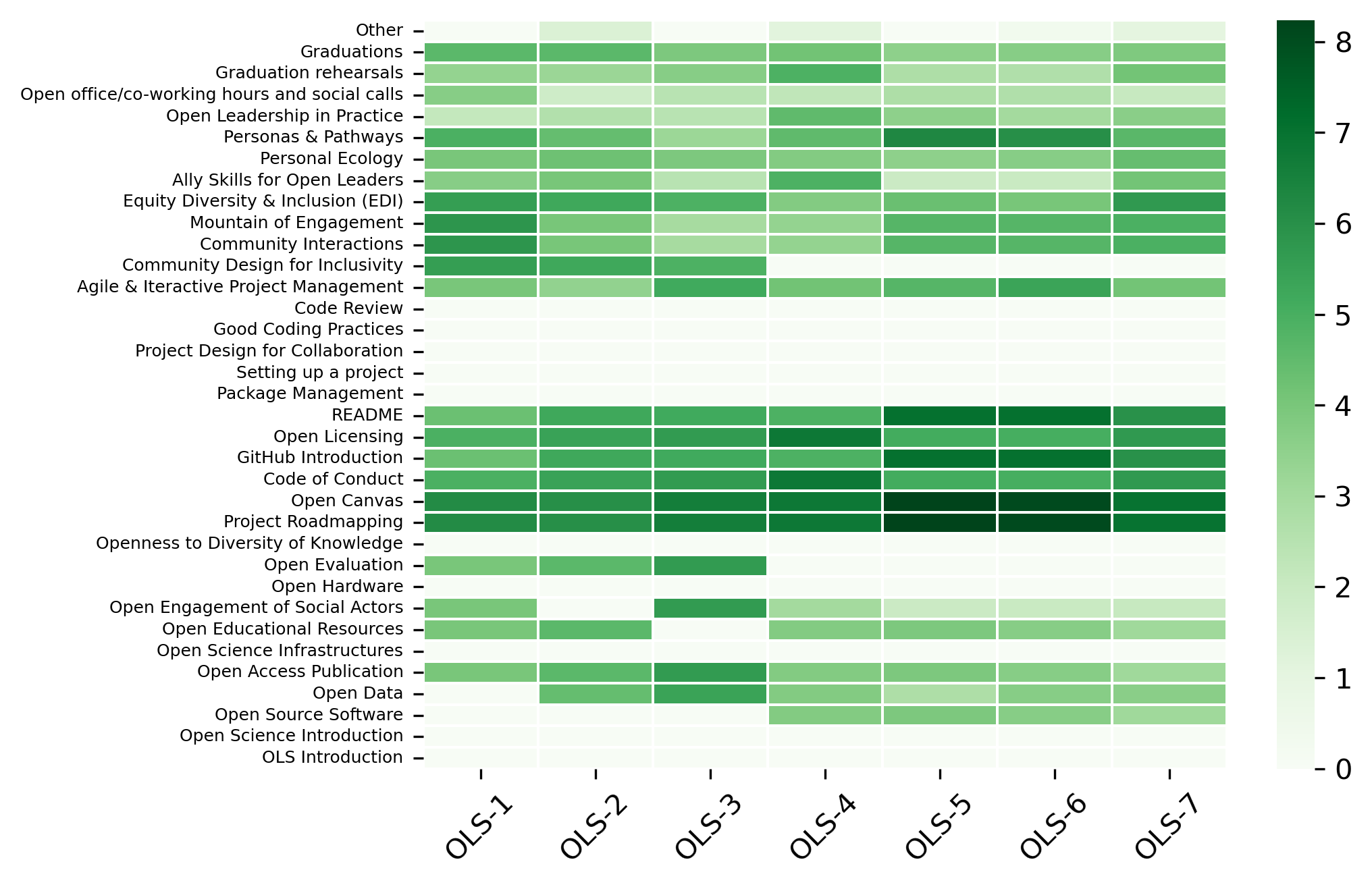
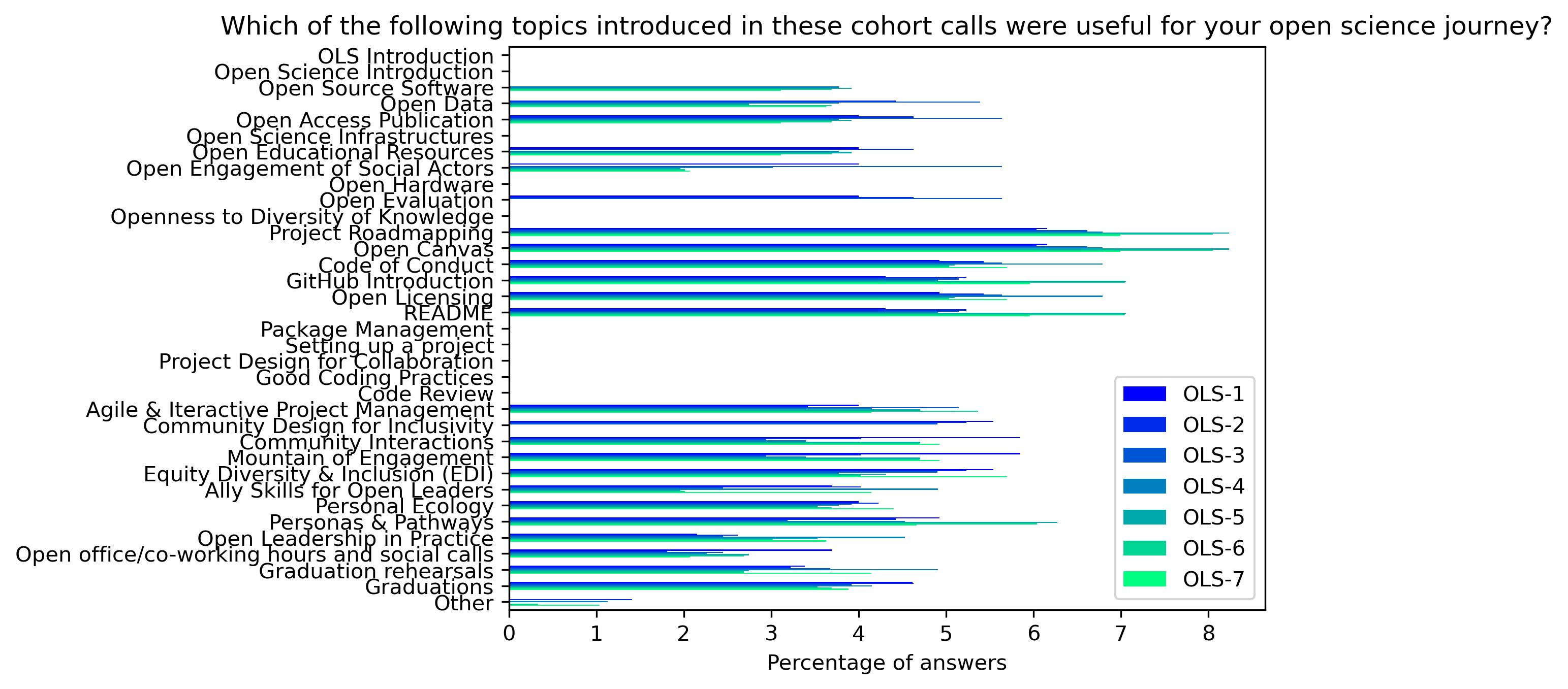
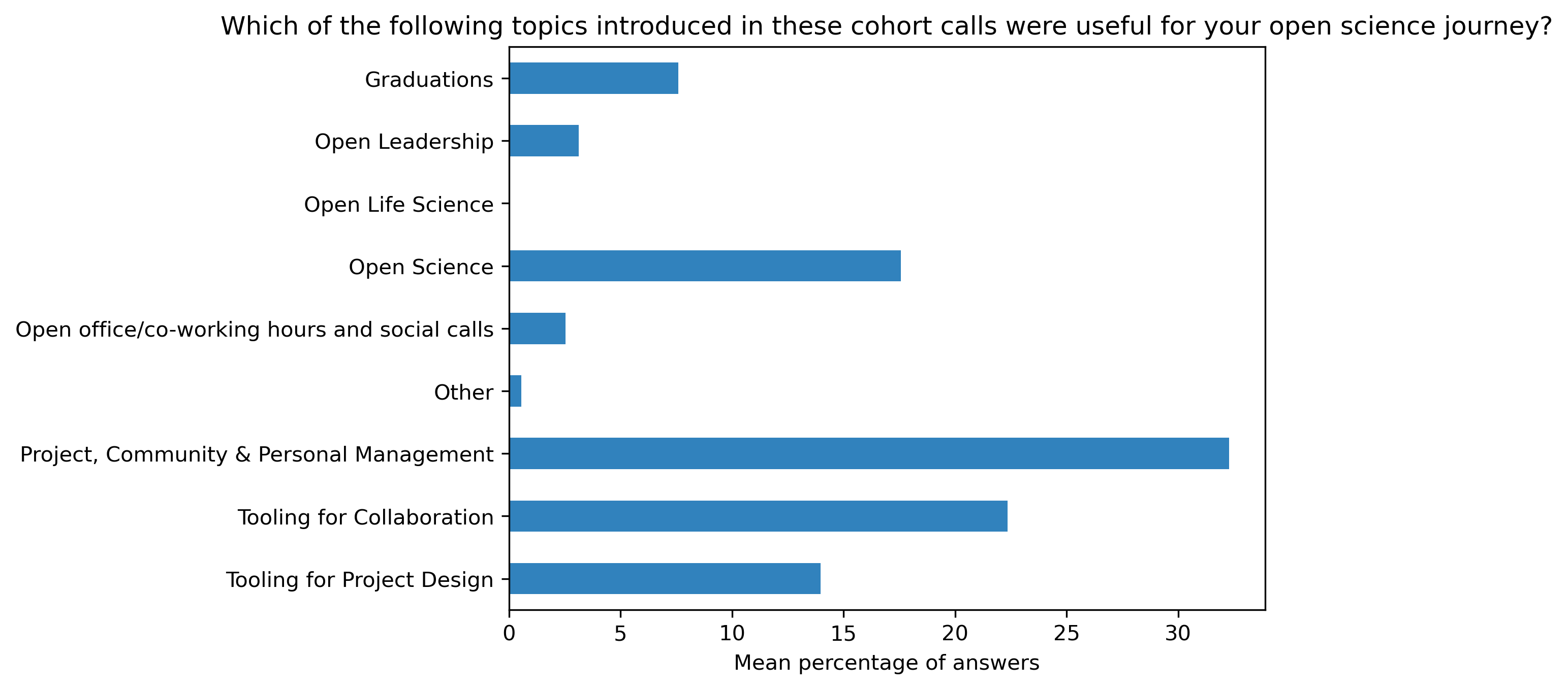
“Which of the following topics introduced in these cohort calls were useful for your open science journey?”#
participant_q4 = {}
other_answer = []
col = "Which of the following topics introduced in these cohort calls were useful for your open science journey?"
answers = [
"OLS Introduction",
"Open Science Introduction",
"Open Source Software",
"Open Data",
"Open Access Publication",
"Open Science Infrastructures",
"Open Educational Resources",
"Open Engagement of Social Actors",
"Open Hardware",
"Open Evaluation",
"Openness to Diversity of Knowledge",
"Project Roadmapping",
"Open Canvas",
"Code of Conduct",
"GitHub Introduction",
"Open Licensing",
"README",
"Package Management",
"Setting up a project",
"Project Design for Collaboration",
"Good Coding Practices",
"Code Review",
"Agile & Iteractive Project Management",
"Community Design for Inclusivity",
"Community Interactions",
"Mountain of Engagement",
"Equity Diversity & Inclusion (EDI)",
"Ally Skills for Open Leaders",
"Personal Ecology",
"Personas & Pathways",
"Open Leadership in Practice",
"Open office/co-working hours and social calls",
"Graduation rehearsals",
"Graduations",
"Other"]
for c in participant_df:
participant_q4[c], oa = get_mcq_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q4_df = pd.DataFrame.from_dict(participant_q4)
participant_q4_df = 100 * participant_q4_df / participant_q4_df.sum()
Other answers:
other_answer
['Breakout rooms were really nice exploit to get to know other participants and share experience. ',
"The ones I haven't ticked are mainly because I haven't caught up with them yet. Generally - all useful (in varying amounts). The less useful ones were only less useful because I knew a moderate amount about them already. Several",
'that I thought I knew a fair amount about',
"turns out I didn't / there was still a lot for me to learn!",
'Breakout rooms was so useful too.',
'As I read this list I am reminded on all I learnt and all I hope to read further into!',
"They were all useful! The ones I've ticked were just the particularly relevant ones at this stage.",
'Actually all were useful',
'those ones were just my favourite ones :)',
'I still need to watch some of the recordings',
"Can't accurately answer as haven't worked through all of the sessions",
'Social entreprise',
'hardware ',
'I have not been able to take advantage of the co-working due to a lack of time',
'but I would have liked to do it.']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q4_df[::-1], cmap='Greens', linewidths=0.5, yticklabels=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal', fontsize=6)
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q4_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
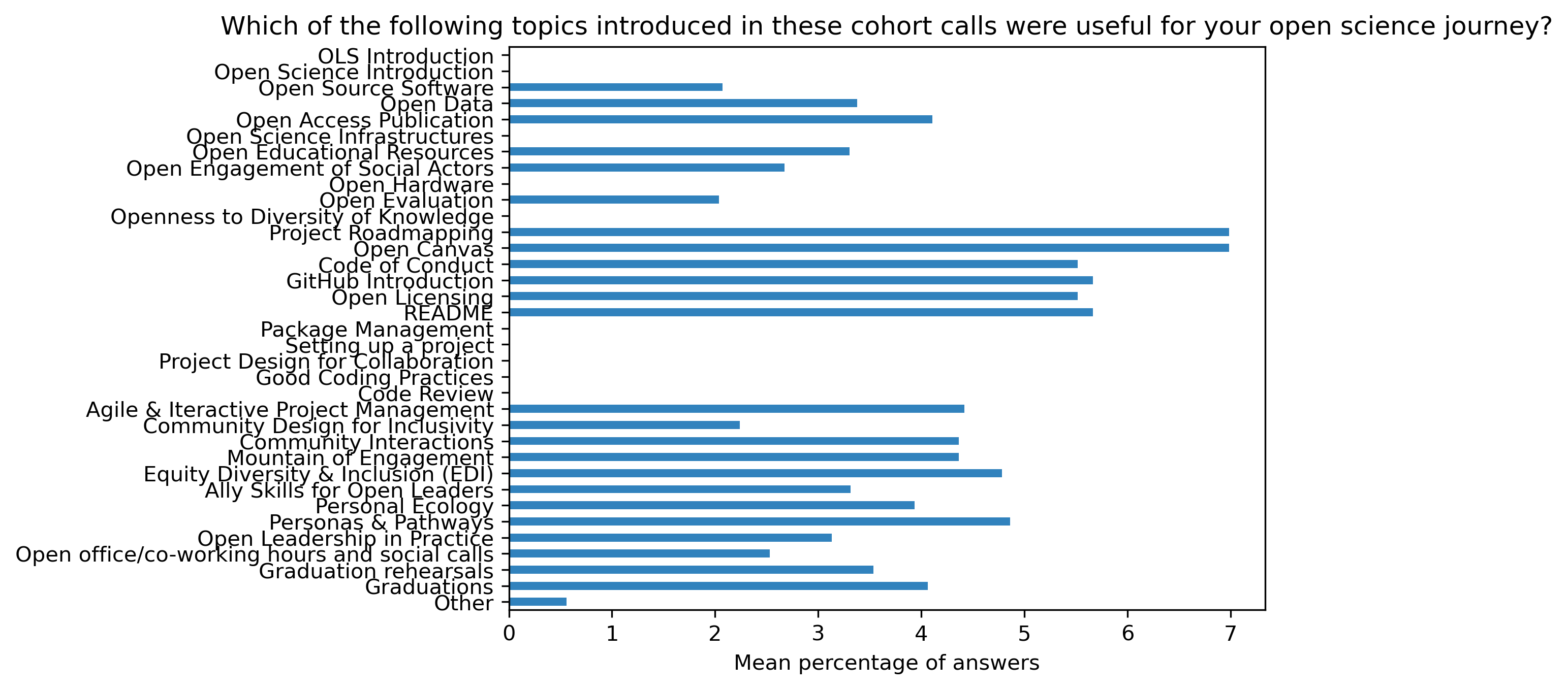
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q4_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
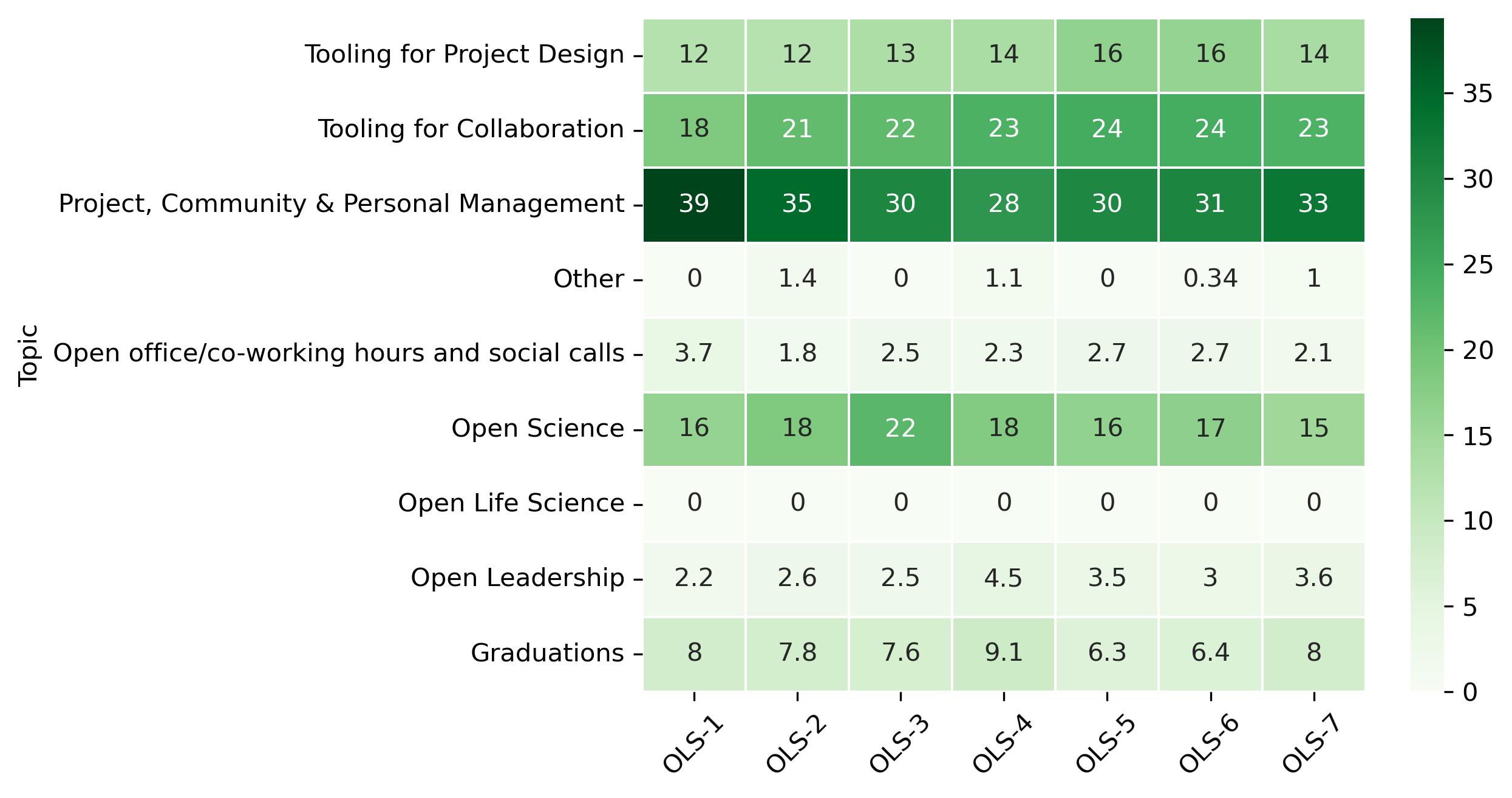
Group by topics
tag_topic_mapping = (pd.read_csv("https://docs.google.com/spreadsheets/d/1sDJLG8RuoShWUQN78lvx_mghBbGfusdzlb1WwYrCbjk/export?format=csv&gid=0")
.replace("Equity, Diversity and ", "Equity Diversity & ", regex=True)
.set_index("Tag")
.drop(columns=["Description", "Comments from Malvika", "Call in OLS-8", "Type", "Week", "Comments"]))
extra_mapping = (pd.DataFrame({
'Tag':['Graduation rehearsals', 'Graduations', 'Open office/co-working hours and social calls', 'Other'],
'Topic':['Graduations','Graduations','Open office/co-working hours and social calls', 'Other']})
.set_index("Tag"))
tag_topic_mapping = pd.concat([tag_topic_mapping, extra_mapping])
participant_q4_by_topic_df = (participant_q4_df.join(tag_topic_mapping)
.groupby(by="Topic")
.sum())
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q4_by_topic_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q4_by_topic_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
plt.ylabel('')
t = plt.title(col)
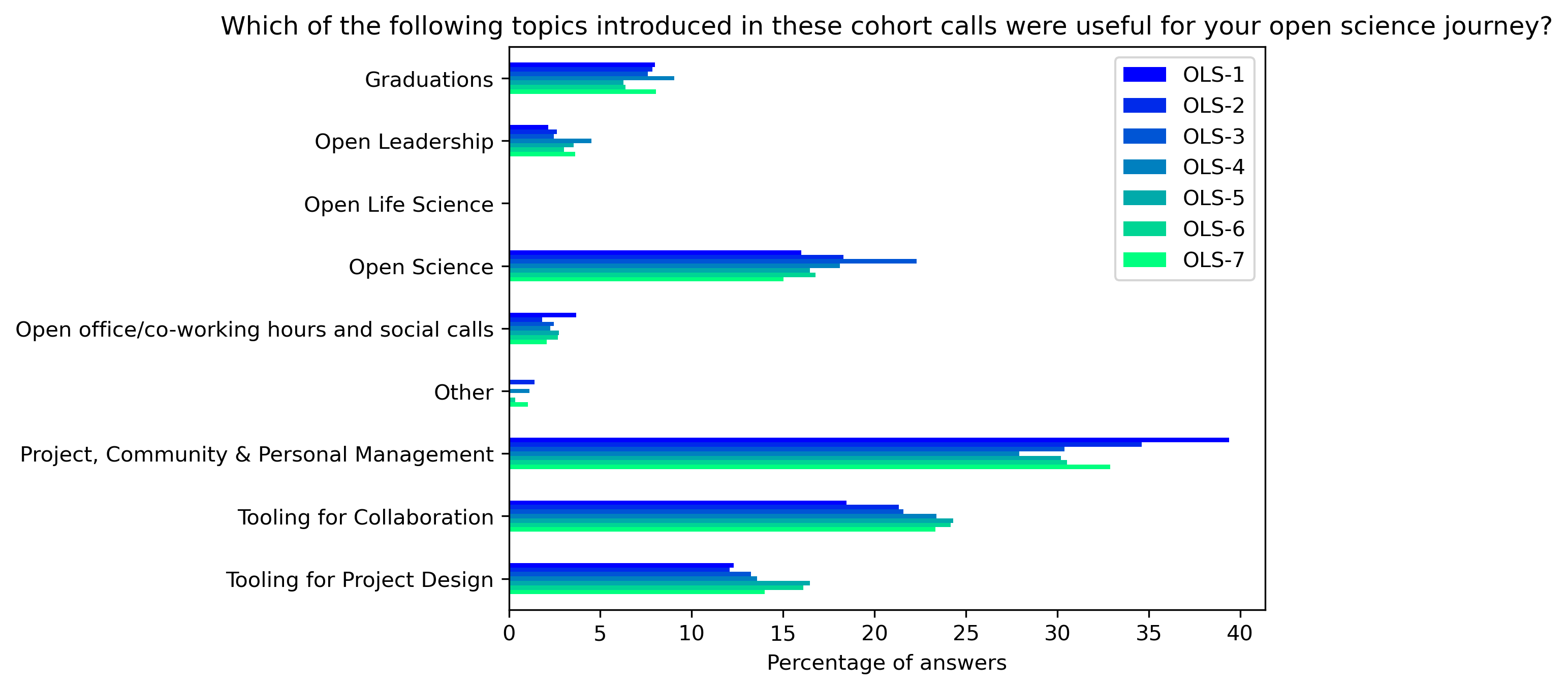
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q4_by_topic_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.ylabel('')
plt.gca().invert_yaxis()
t = plt.title(col)
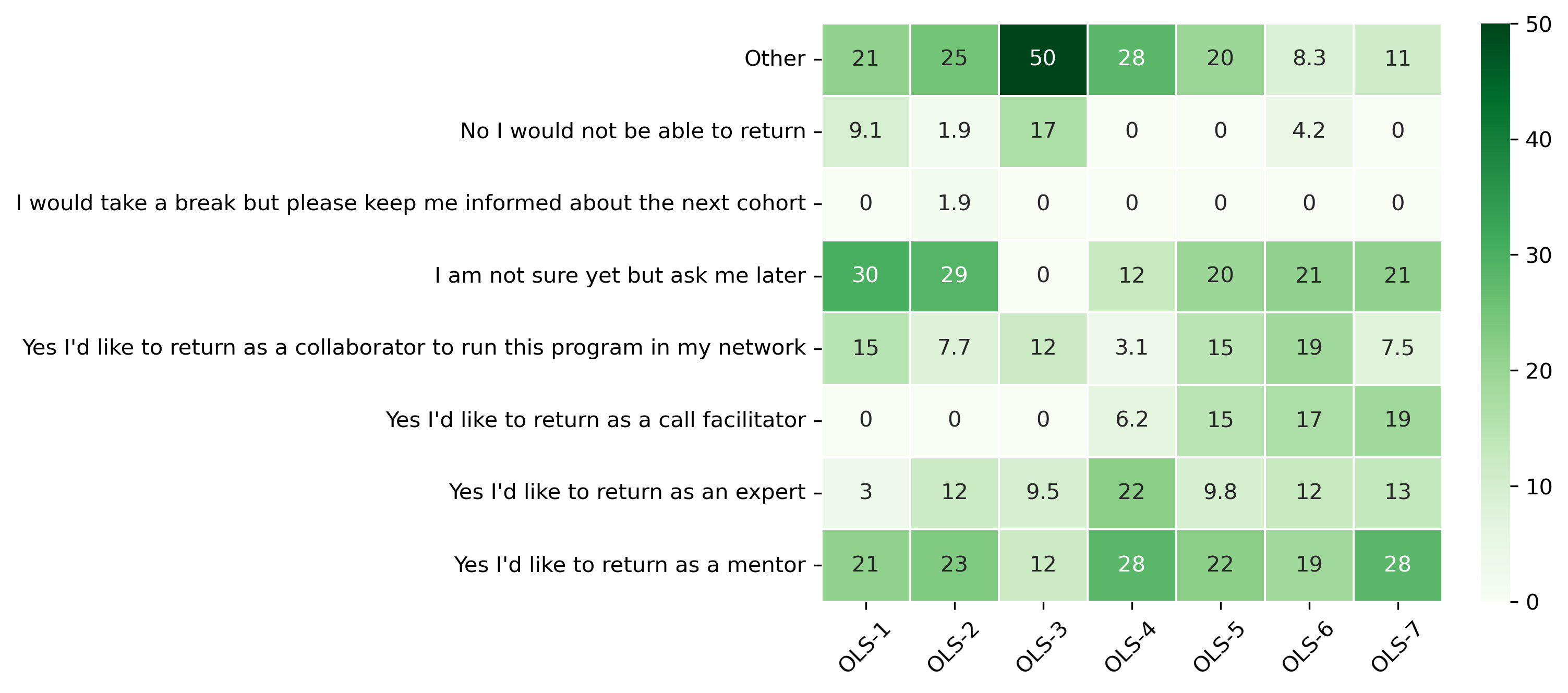
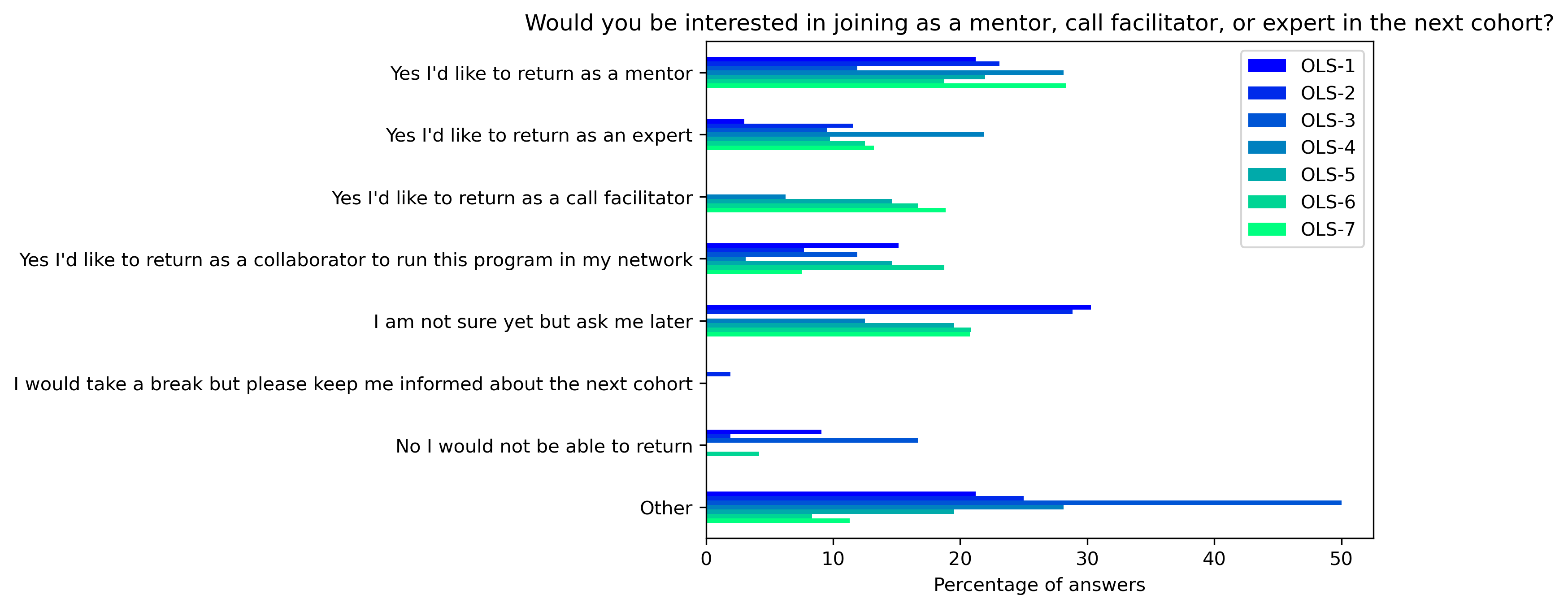
“Would you be interested in joining as a mentor, call facilitator, or expert in the next cohort?”#
participant_q5 = {}
other_answer = []
col = "Would you be interested in joining as a mentor, call facilitator, or expert in the next cohort?"
answers = [
"Yes I'd like to return as a mentor",
"Yes I'd like to return as an expert",
"Yes I'd like to return as a call facilitator",
"Yes I'd like to return as a collaborator to run this program in my network",
"I am not sure yet but ask me later",
"I would take a break but please keep me informed about the next cohort",
"No I would not be able to return",
"Other"]
for c in participant_df:
participant_q5[c], oa = get_mcq_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q5_df = pd.DataFrame.from_dict(participant_q5)
participant_q5_df = 100 * participant_q5_df / participant_q5_df.sum()
Other answers:
other_answer
['',
'I would like to receive mentoring training and I will be good to help a mentor in some of the mentoring work in either OLS-2 or subsequent cohorts.',
"I don't feel qualified yet",
'and I feel I would do a disservice to the mentee',
'definitely',
"tho depending on the role. I'd love to be a mentor but not sure my experience will be as useful to academics ",
"I'm not sure I have the skills as a mentor/expert?",
'Well',
'I would love to but I dont think I have suffiecent expertise yet. ',
'I would like to return as a mentor or expert but not in the next year since I promised myself to not commit to more projects. Please keep in touch though!',
'Not yet actually. I attended this project as a helper. My contribution was not much. I surely need to improve myself. Maybe after an individual attendence to a project for OLS-3',
'I can find opportunity for improvements. Then I love to join as a mentor.',
'I am open to discussing further engagement but do not want to take on more than I am equipped to deliver.',
"I'd love to be involved in the future (e.g.",
'as a mentor or expert',
'as I indicated)',
'but probably not until next year at least',
'as I need to prioritize some other aspects of my life/work this year. ',
'I would like to return to OLS',
"but right now I'm crazy busy and need to focus on some work projects. I'm happy to do coordinate a coworking call for OLS-3 (or something similar which is low threshold) and I can be in the loop for OLS-4 or later for a mentor/expert role (I'm happily assuming it continues forever) ",
'I am not sure yet but ask me later when you have launched OLS-4',
'I may join as a mentee cause ı need to learn more',
'still ! :)',
'Please contact me for OLS-5 :)',
'Maybe OLS-5. I will need to re-assimilate all I was taught in cohort',
'for OLS-4 or later (whatever can fit your )',
"but I'd like to :)",
"Not sure whether I'm totally prepared for it",
'No',
'I would not be able to return to OLS-5',
"I don't have much experience as an active OS community member or developer. I would feel comfortable with mentoring someone taking their first steps on programming or web dev.",
"I'd like to return as a mentor not now",
'but in the near future (e. g.',
'OLS-6)',
'I have applied for OLS-5 as a mentee to build my project further.',
'No',
'',
'I would not be able to return to OLS-6',
'I will return as a mentee',
'I would take a break but please keep me informed about the next cohort?',
'',
'I will return as a mentee',
'I would take a break but please keep me informed about the next cohort?',
'No',
'I would not be able to return to OLS-8',
"I don't know how but I'd like to stay involved!",
"I'd like to help but would need to know expected time allocations"]
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q5_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q5_df.plot.barh(ax=ax, colormap=colors['participant_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q5_df.mean(axis=1).plot.barh(ax=ax, color=colors['participants'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)

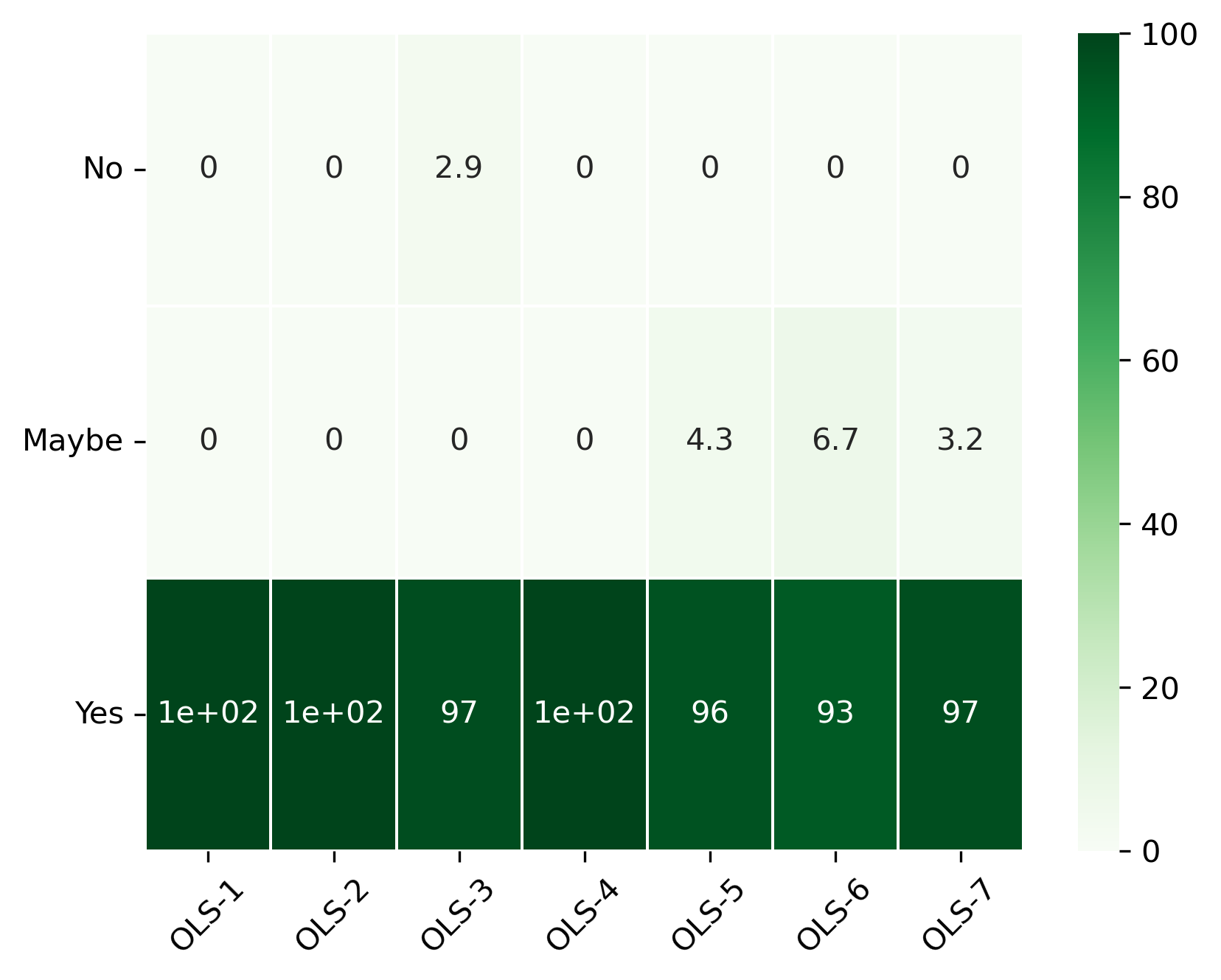
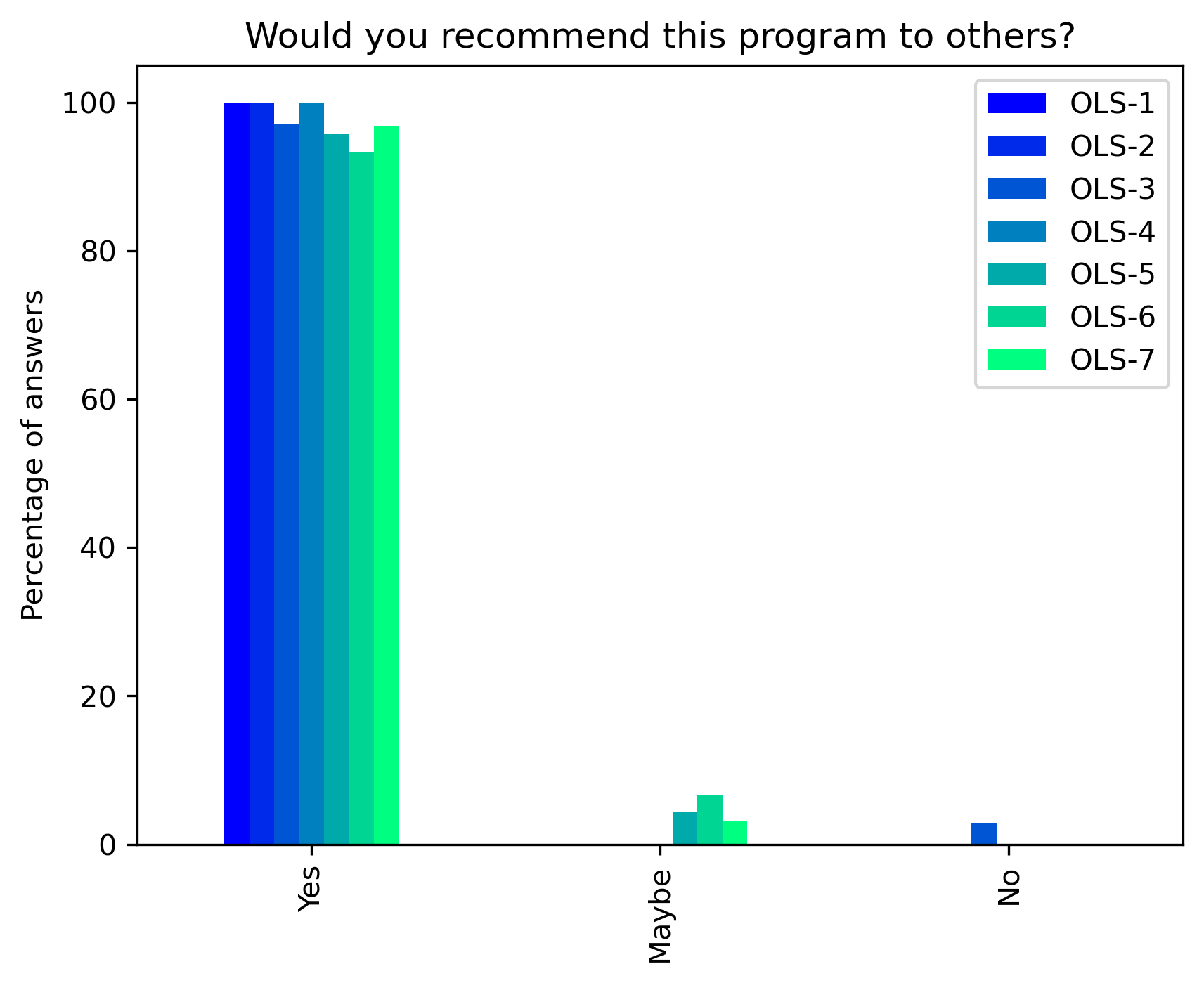
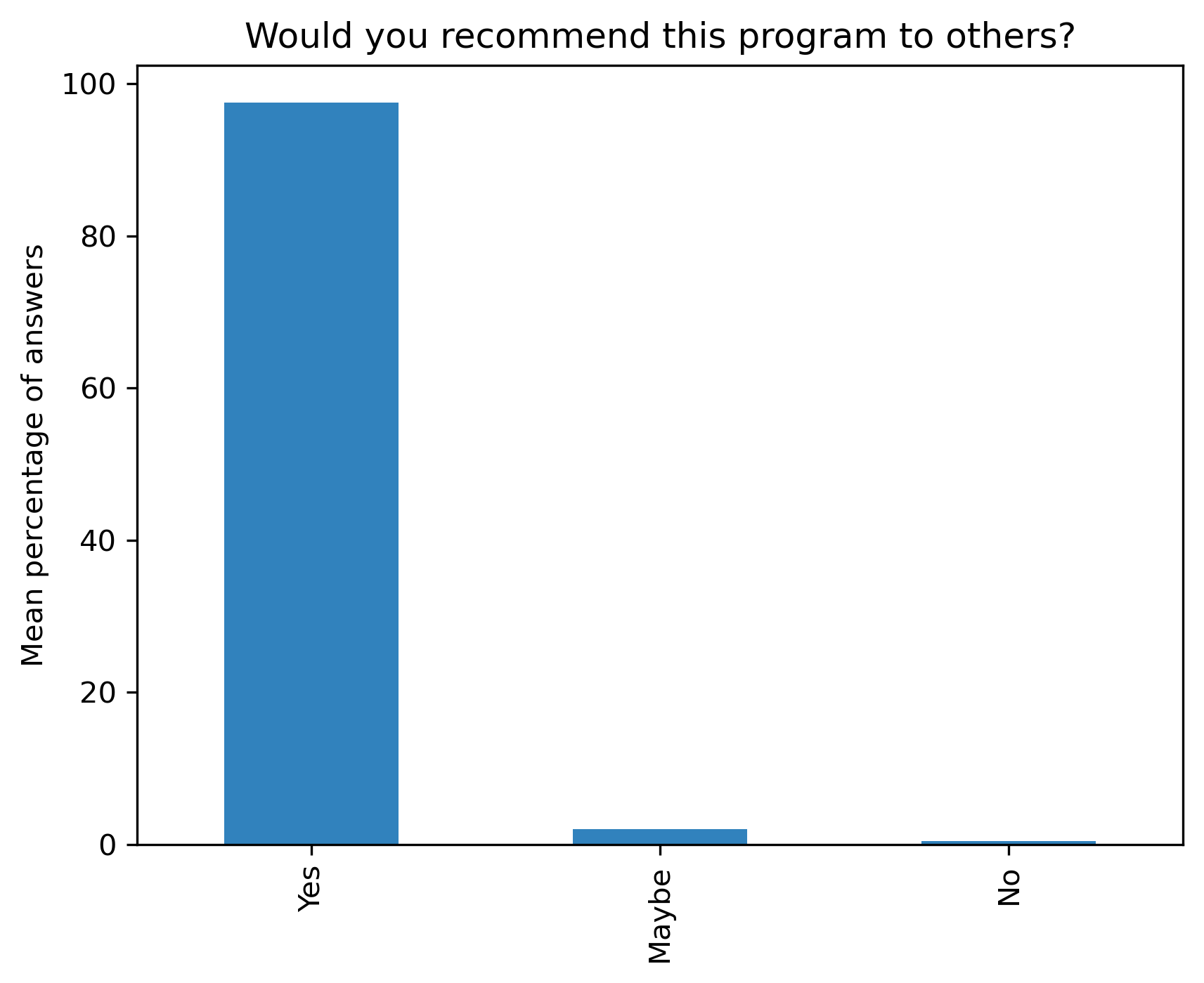
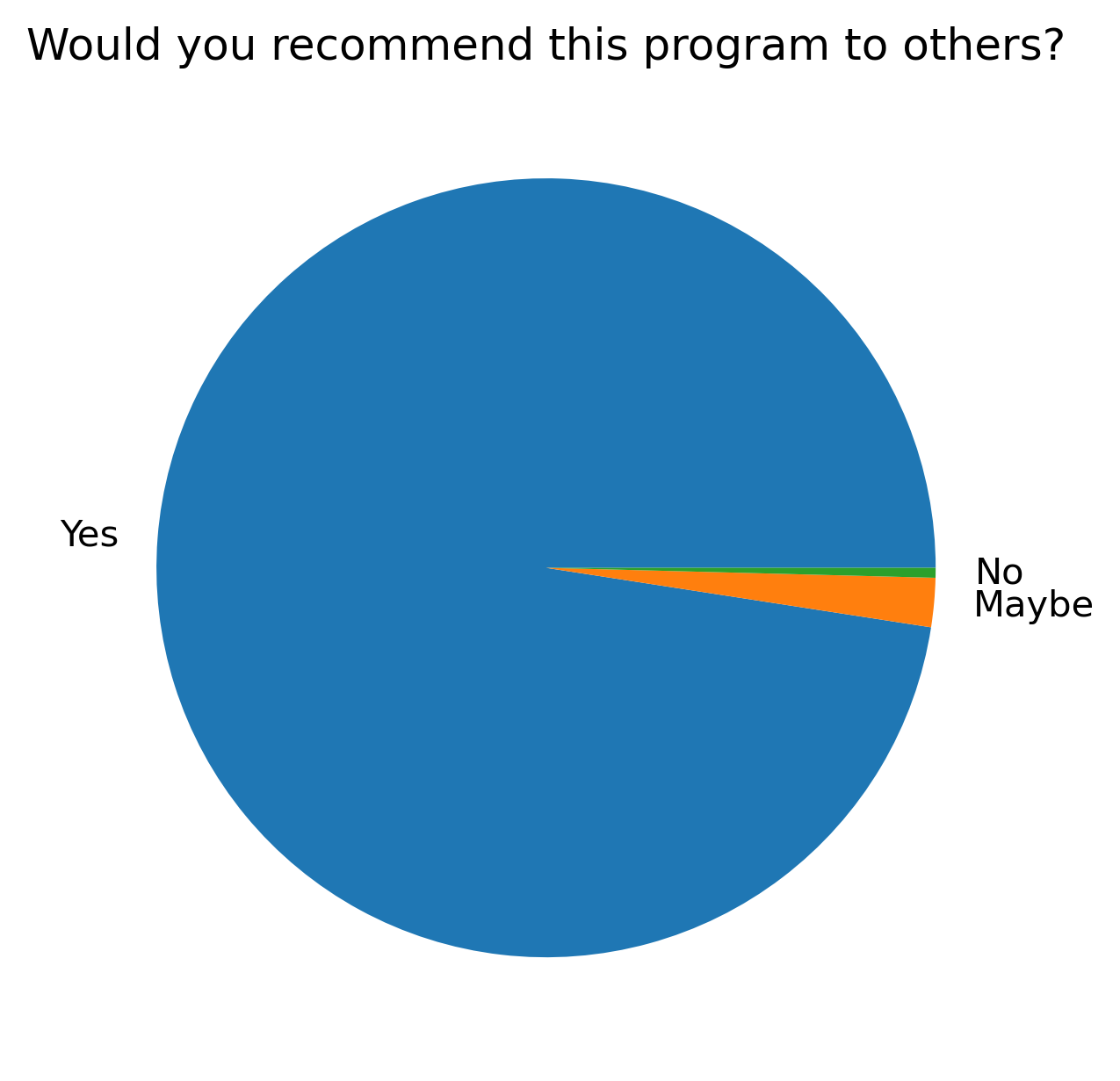
“Would you recommend this program to others?”#
participant_q6 = {}
other_answer = []
col = "Would you recommend this program to others?"
answers = [
"Yes",
"Maybe",
"No"]
for c in participant_df:
participant_q6[c], oa = get_question_possible_answers_counts(col, participant_df[c], answers)
other_answer += oa
participant_q6_df = pd.DataFrame.from_dict(participant_q6)
participant_q6_df = 100 * participant_q6_df / participant_q6_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(participant_q6_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q6_df.plot.bar(ax=ax, colormap=colors['participant_colormap'])
plt.ylabel('Percentage of answers')
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q6_df.mean(axis=1).plot.bar(ax=ax, color=colors['participants'])
plt.ylabel('Mean percentage of answers')
t = plt.title(col)
fig, ax = plt.subplots()
fig.set_dpi(300)
participant_q6_df.mean(axis=1).plot.pie()
t = plt.title(col)
Mentors#
url = "https://docs.google.com/spreadsheets/d/1JOnjaojSYz8J0Yg27IS73MtraIL36BgtavJWlvBuGtI/export?format=csv"
cohort_gid = {
'OLS-1': '922543579',
'OLS-2': '293719636',
'OLS-3': '901891477',
'OLS-4': '186857041',
'OLS-5': '0',
'OLS-6': '227796069',
'OLS-7': '1608148546'
}
mentor_df = {}
answers = {}
for c in cohort_gid:
mentor_df[c] = (
pd.read_csv(f"{url}&gid={cohort_gid[c]}")
.dropna(axis=1,how='all')
.fillna("")
.replace(c, "cohort",regex=True)
.replace("I am not sure yet, but ask me later when you have launched OLS-2", "I am not sure yet but ask me later", regex=True)
.replace("I am not sure yet, but ask me later when you have launched cohort", "I am not sure yet but ask me later", regex=True)
.replace("I am not sure yet, but ask me later", "I am not sure yet but ask me later", regex=True)
.replace("Yes I'd like to return as a collaborator to run an OLS cohort for my network", "Yes I'd like to return as a collaborator to run this program in my network", regex=True)
.replace("No, I would not be able to return to OLS-2", "No I would not be able to return", regex=True)
.replace("No, I would not be able to return to cohort", "No I would not be able to return", regex=True)
.replace("No, I would not be able to return to OLS-4", "No I would not be able to return", regex=True)
.replace("I would not be able to return to OLS-3 but I am hopeful to return to OLS-4 with an active role.", "I would take a break but please keep me informed about the next cohort", regex=True)
.replace("No, but only because I really would not have the time", "No I would not be able to return", regex=True)
.replace("Maybe in OLS-7?", "I would take a break but please keep me informed about the next cohort", regex=True)
)
answers[c] = mentor_df[c].shape[0]
answer_s = pd.Series(answers)
answer_s
fig, ax = plt.subplots()
fig.set_dpi(300)
answer_s.plot.bar(ax=ax, color=colors['mentors'])
plt.ylabel('Number of answers to the survey')
Text(0, 0.5, 'Number of answers to the survey')
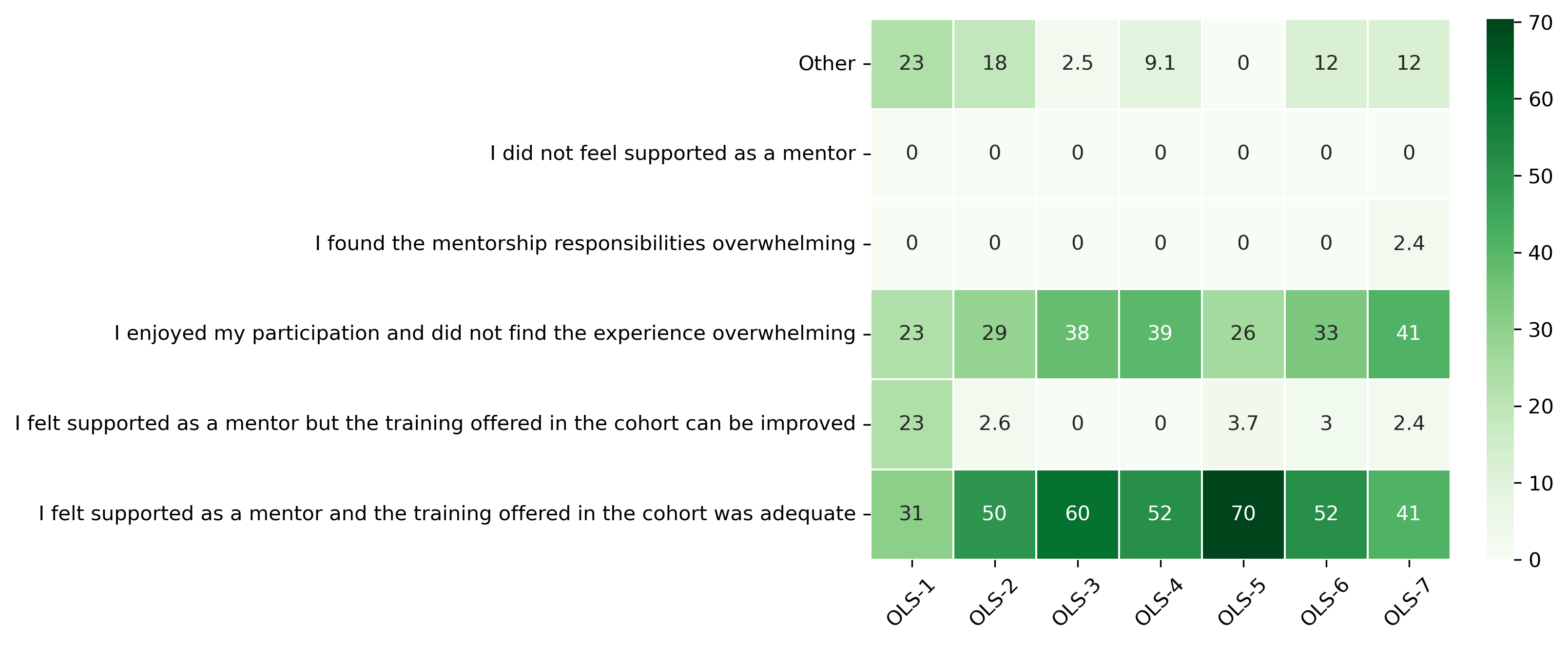
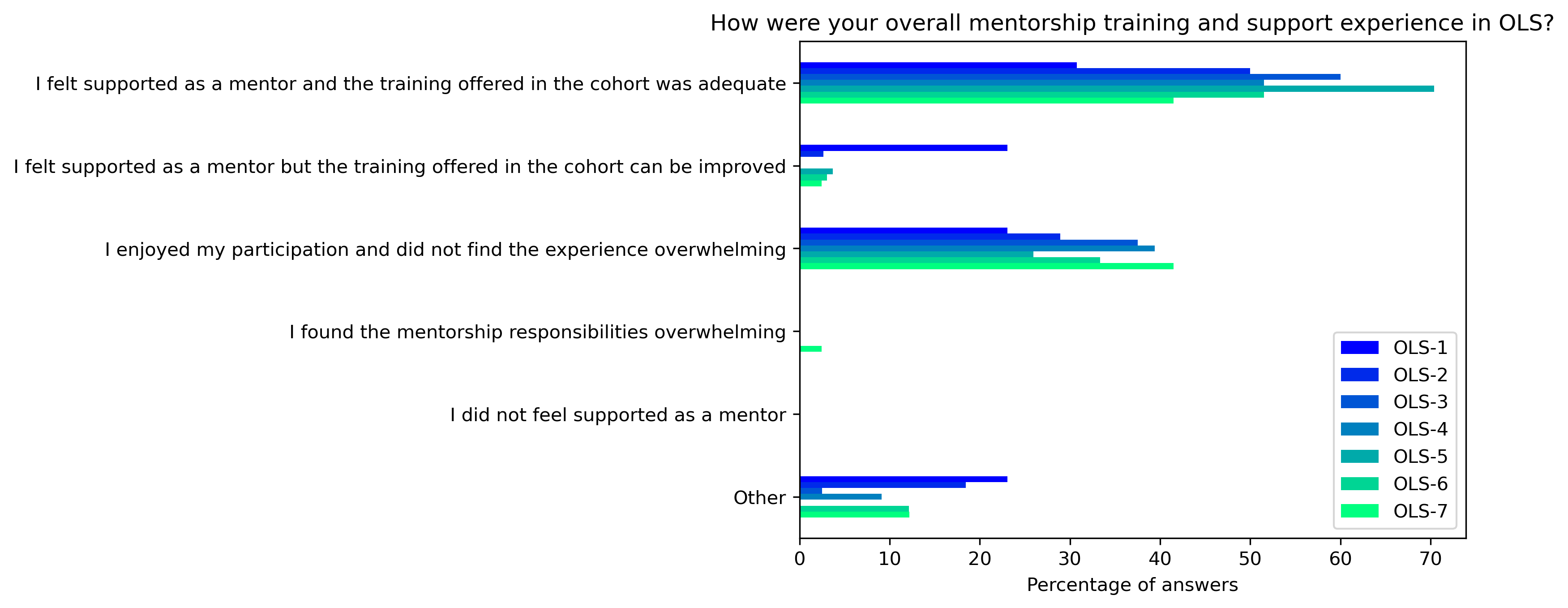
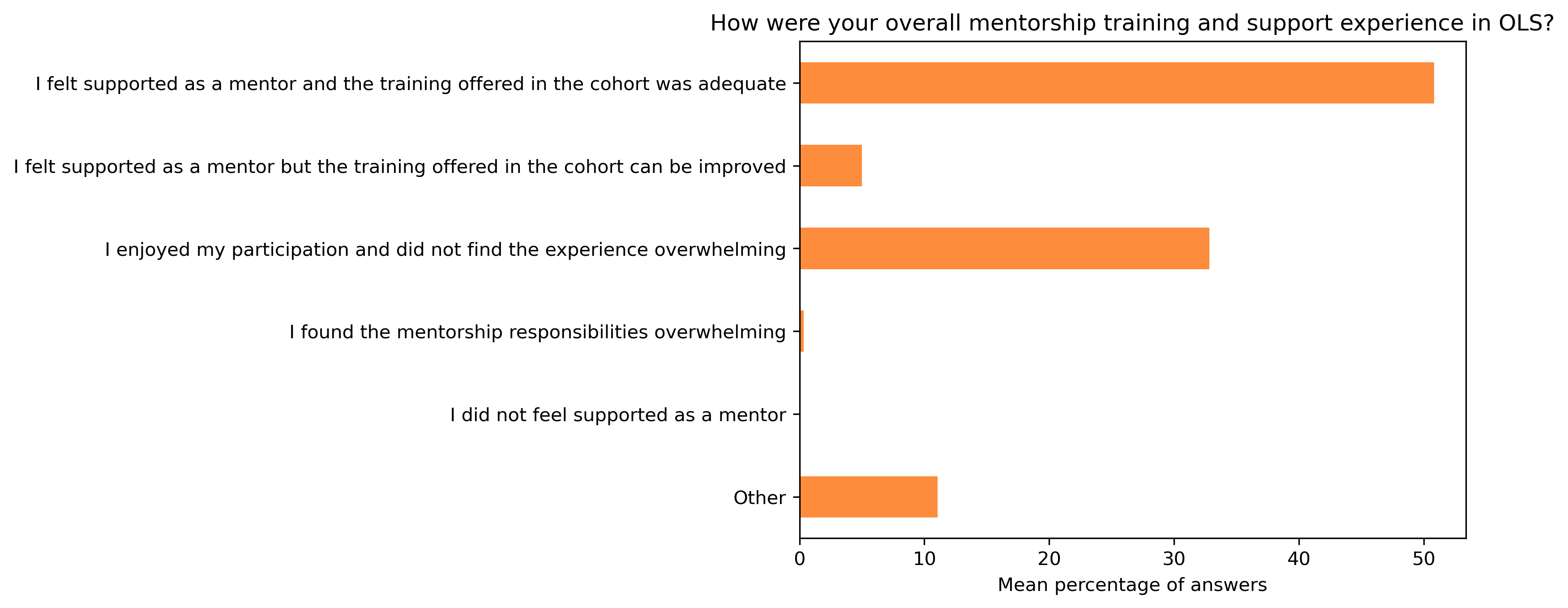
“How were your overall mentorship training and support experience in OLS?”#
Possible answers:
I felt supported as a mentor and the training offered in the cohort was adequate
I felt supported as a mentor but the training offered in the cohort can be improved
I enjoyed my participation and did not find the experience overwhelming
I found the mentorship responsibilities overwhelming
I did not feel supported as a mentor
Other
mentor_q1 = {}
other_answer = []
col = "How were your overall mentorship training and support experience in OLS?"
answers = [
"I felt supported as a mentor and the training offered in the cohort was adequate",
"I felt supported as a mentor but the training offered in the cohort can be improved",
"I enjoyed my participation and did not find the experience overwhelming",
"I found the mentorship responsibilities overwhelming",
"I did not feel supported as a mentor",
"Other"]
for c in mentor_df:
mentor_q1[c], oa = get_mcq_possible_answers_counts(col, mentor_df[c], answers)
other_answer += oa
mentor_q1_df = pd.DataFrame.from_dict(mentor_q1)
mentor_q1_df = 100 * mentor_q1_df / mentor_q1_df.sum()
Other answers:
other_answer
['I missed out on some mentor trainings (due to scheduling conflicts',
'and my feeling comfortable from previous experience mentoring for MozOL)',
'but the ones I attended were great! ',
'It would have been good to maybe have a reflection / consolidation session for mentors at the end of the programme but I really appreciated the training organised and the support from other mentors ',
'I found the experience frustrating. I think that the mentees and I failed to clarify and describe what we expected from the relationship. My feeling through the whole program was that they were looking for a mentor who gave them specific knolwedge',
'ideas for solutions to their problems - while I wanted to be more of a coach',
'someone to listen and provide structure to their discussions. I was left feeling that i had done a poor job as a mentor.',
'I found mentoring this project really inspiring. Sometimes Annalee had queries I did not know the answer to but the community allowed me to suggest others for her to engage with (thanks all!) and we talked through the challenges together.',
'I could not invest as much time as I wanted. I understimated the issue of getting to meeting in the evenings due to time differences',
'Due to circumstances',
'the mentees were not able to fully engage with the project and OLS in general.',
'enriching and overall great. ',
'I expressed some doubts and insecurity about the future relationship with my mentee becasue of age and gender difference and it was great to have Paz and Mayya checking in about how it was going :)',
'Some more (structured) communication between mentors would be great.',
'For this round of mentoring I found it tougher to engage because of other commitments. ',
'I felt supported as a mentor and the training offered in the OLS-6 was adequate',
'Maybe it could be useful for future mentors to plan their training before they meet their mentees for the first time so they feel more confident. ']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(mentor_q1_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q1_df.plot.barh(ax=ax, colormap=colors['mentor_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q1_df.mean(axis=1).plot.barh(ax=ax, color=colors['mentors'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
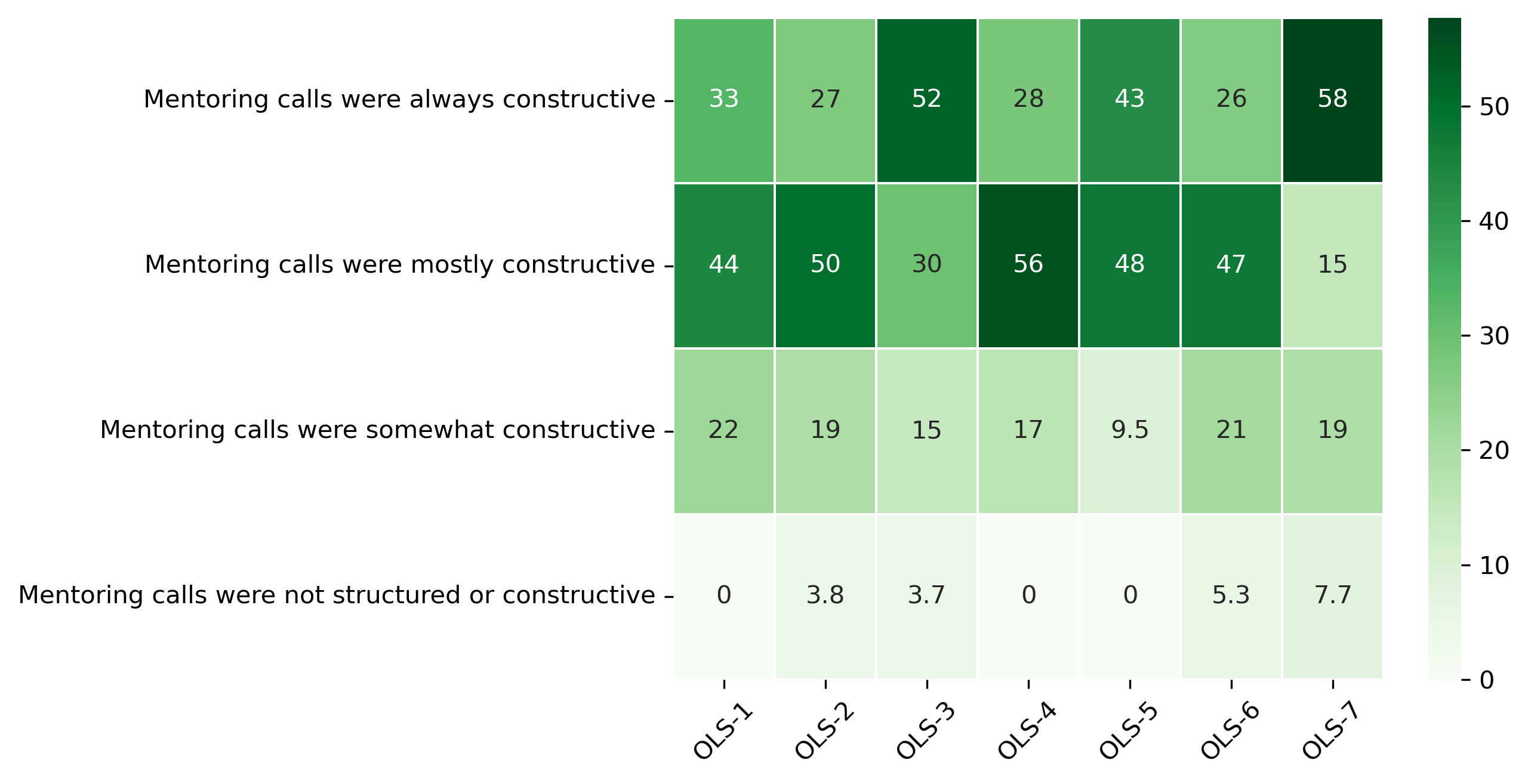
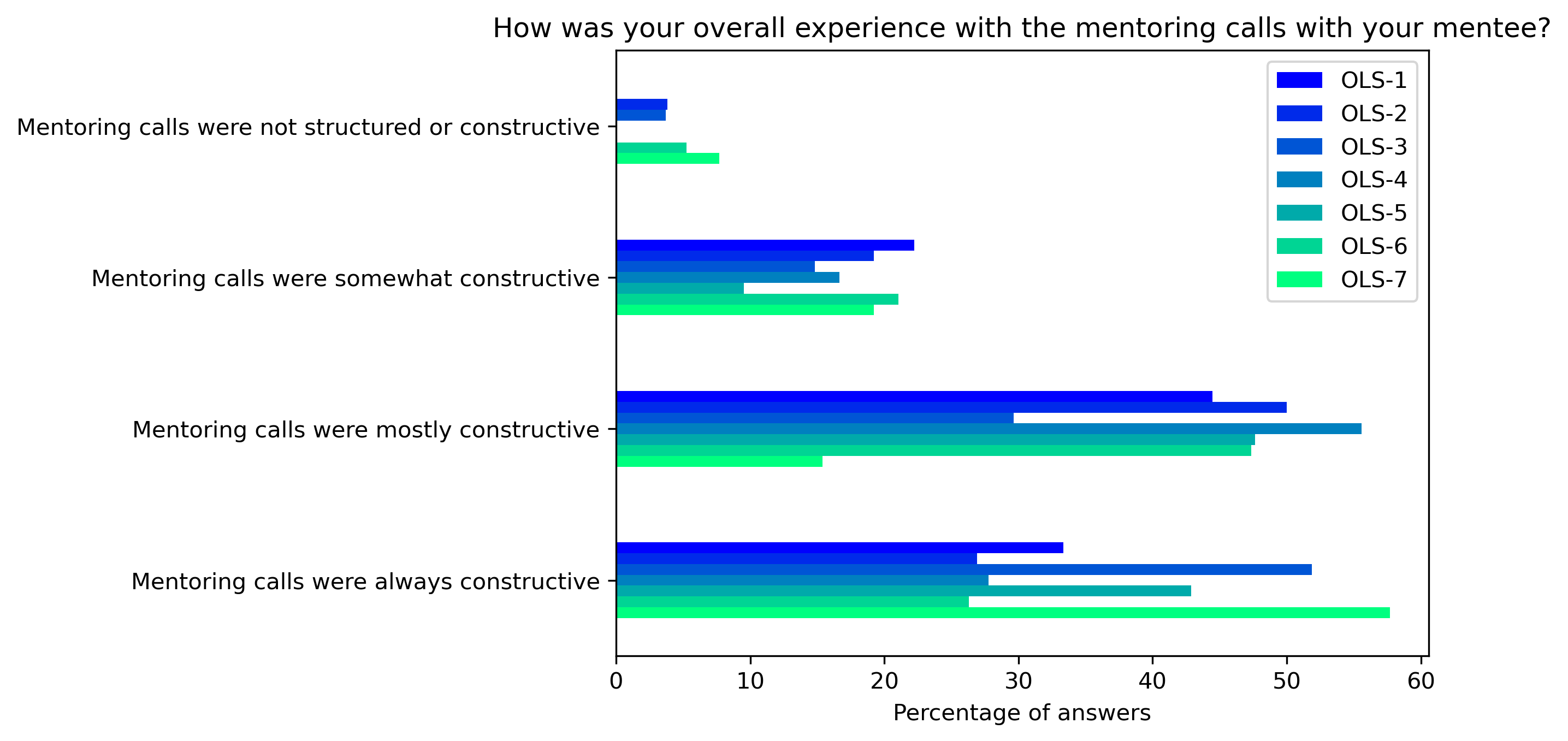
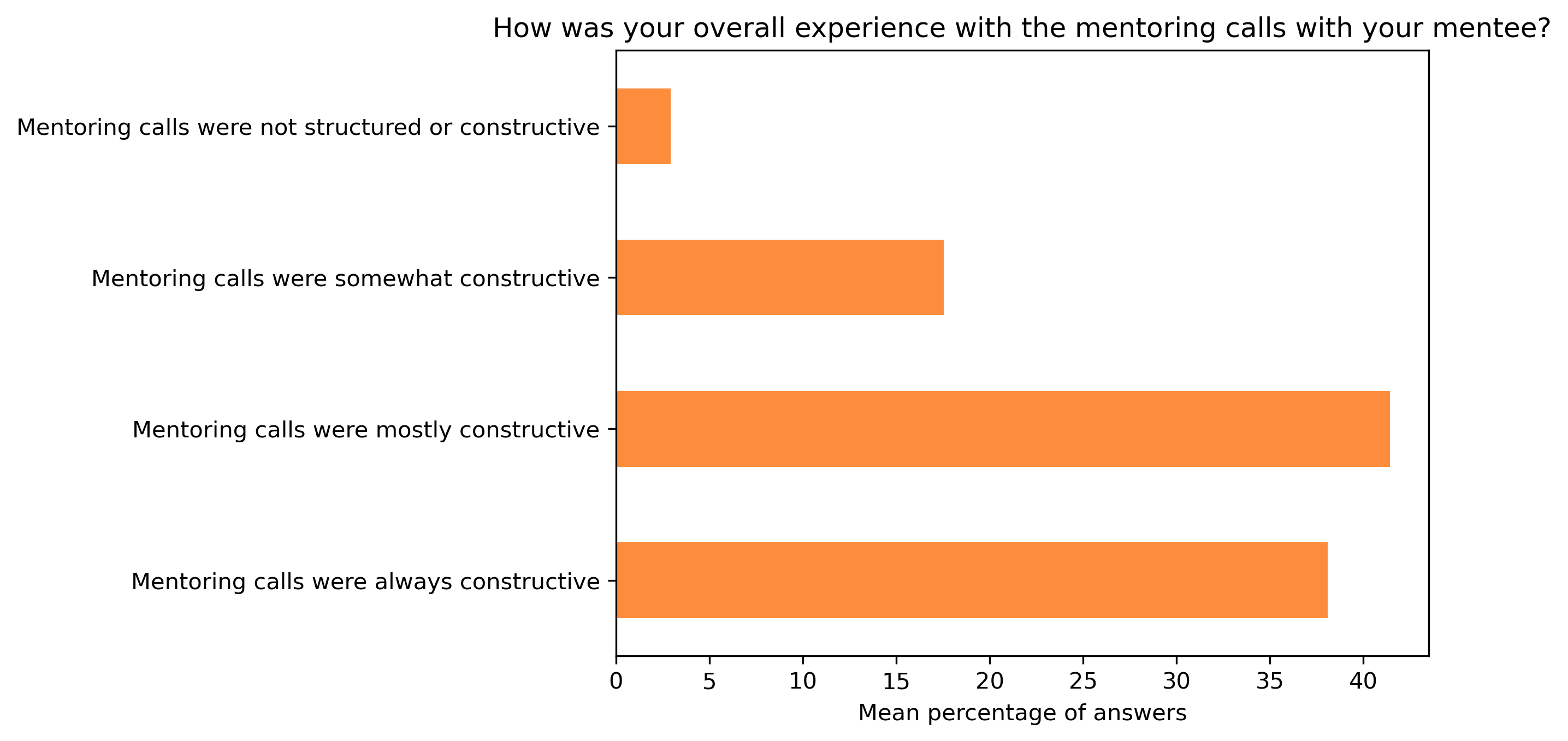
“How was your overall experience with the mentoring calls with your mentee?”#
mentor_q2 = {}
other_answer = []
col = "How was your overall experience with the mentoring calls with your mentee?"
answers = [
"Mentoring calls were not structured or constructive",
"Mentoring calls were somewhat constructive",
"Mentoring calls were mostly constructive",
"Mentoring calls were always constructive"]
for c in mentor_df:
mentor_q2[c], oa = get_mcq_possible_answers_counts(col, mentor_df[c], answers)
other_answer += oa
mentor_q2_df = pd.DataFrame.from_dict(mentor_q2)
mentor_q2_df = 100 * mentor_q2_df / mentor_q2_df.sum()
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(mentor_q2_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q2_df.plot.barh(ax=ax, colormap=colors['mentor_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
plt.title(col)
#plt.savefig('../', bbox_inches='tight')
Text(0.5, 1.0, 'How was your overall experience with the mentoring calls with your mentee?')
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q2_df.mean(axis=1).plot.barh(ax=ax, color=colors['mentors'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
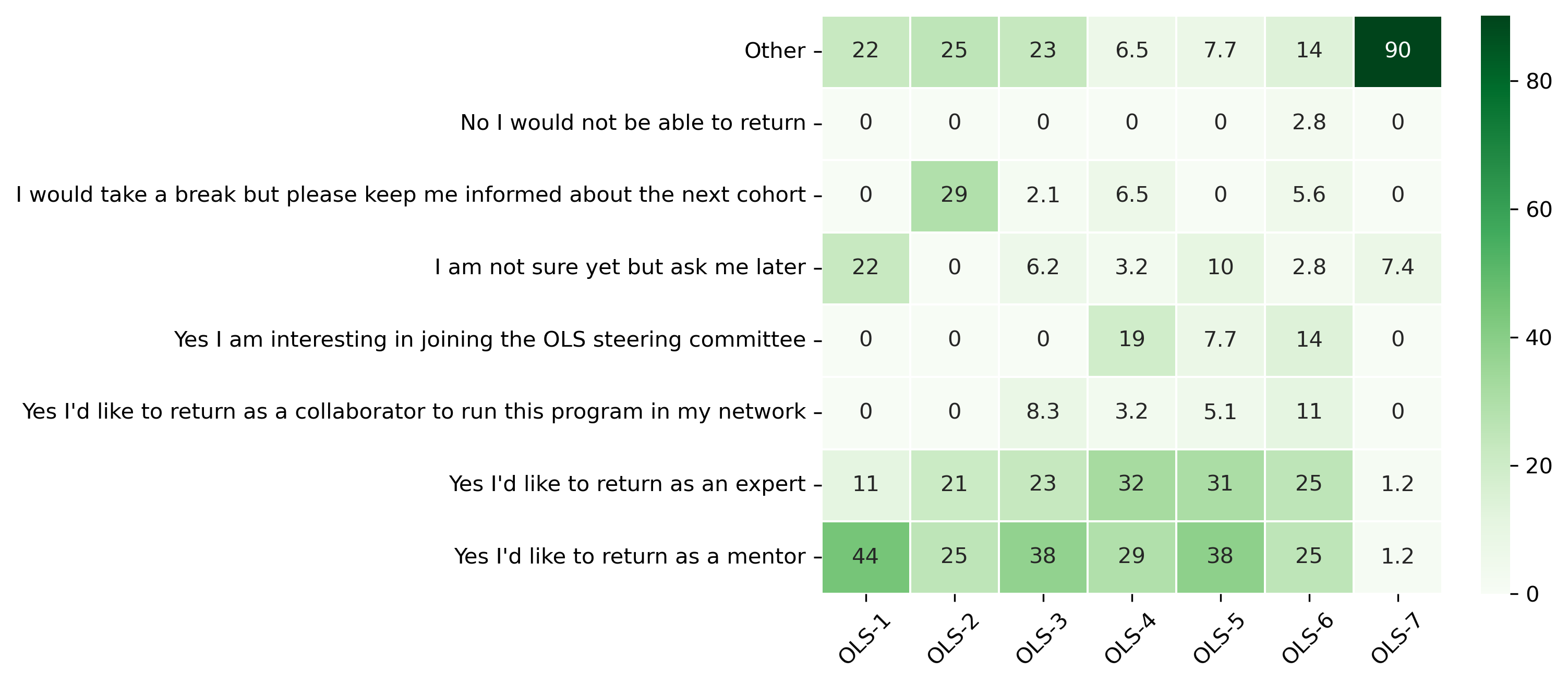
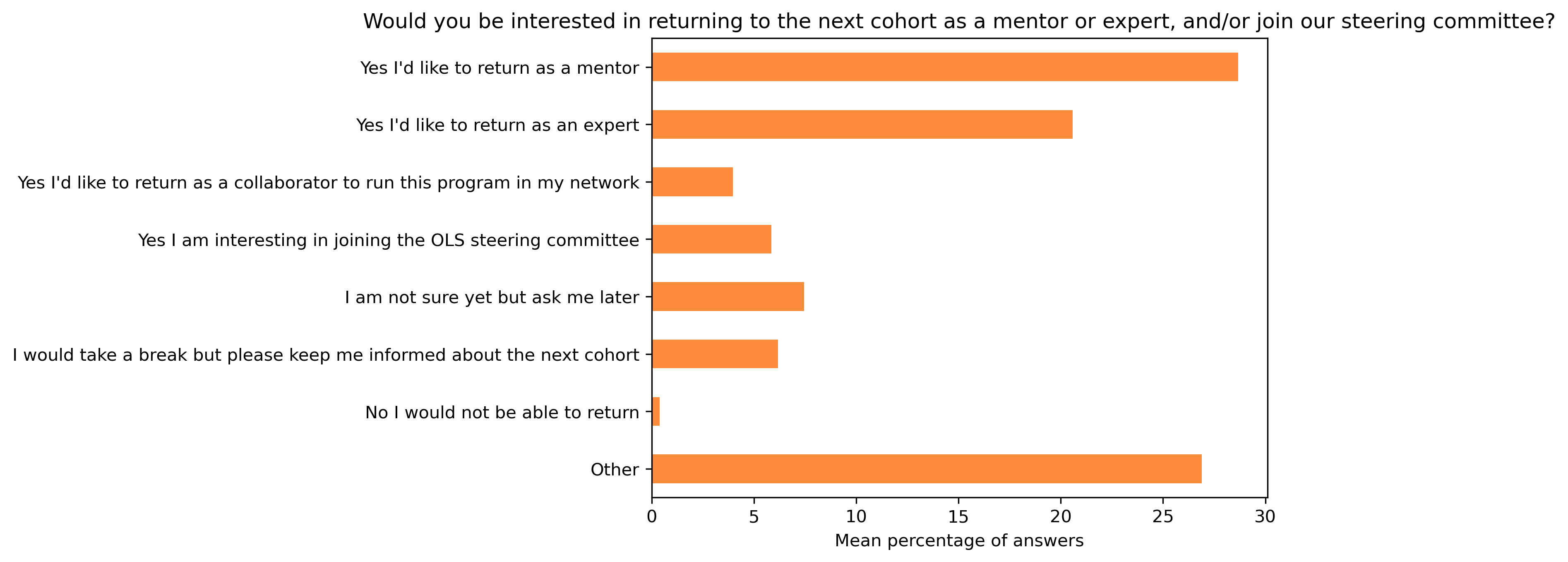
“Would you be interested in returning to the next cohort as a mentor or expert, and/or join our steering committee?”#
mentor_q3 = {}
other_answer = []
col = "Would you be interested in returning to the next cohort as a mentor or expert, and/or join our steering committee?"
answers = [
"Yes I'd like to return as a mentor",
"Yes I'd like to return as an expert",
"Yes I'd like to return as a collaborator to run this program in my network",
"Yes I am interesting in joining the OLS steering committee",
"I am not sure yet but ask me later",
"I would take a break but please keep me informed about the next cohort",
"No I would not be able to return",
"Other"]
for c in mentor_df:
mentor_q3[c], oa = get_mcq_possible_answers_counts(col, mentor_df[c], answers)
other_answer += oa
mentor_q3_df = pd.DataFrame.from_dict(mentor_q3)
mentor_q3_df = 100 * mentor_q3_df / mentor_q3_df.sum()
Other answers:
other_answer
['Yes',
"but I don't know how yet! Could be any of the three ways...",
'',
'but maybe relevant only if there is applicants from ecology / biodiversity fields like it was in OLS2',
'I have signed up as both an expert and mentor for OLS-3',
'I would like to not use platform that collects data (more details in email)',
"I've signed up as both expert and mentor but I'm happy to relay the baton and give this excellent opportunity to others.",
'I am not sure yet but ask me later when you have launched OLS-4',
'mentor or expert. I just need to think it through/discuss.',
'I am keen to open this up and invite more building energy researchers - this network is developing informally so I would like to plan further developing a community',
'either as a mentee',
'I should have more time in September to be able to put in more time into this during working hours: especially if I can get the credits for the PhDs sorted out and have some of them apply. ',
"I'd like to take a break for OLS-4",
'but please contact me for OLS-5 :)',
'I checked yes to the collaborator option',
'but actually',
'I want to know what this means exactly.',
'No',
'I would not be able to return',
'I love this community',
'I would like to continue being involved in OLS',
'but need to assess my possible time commitments over the next few months first',
'Participant',
'Also happy to be a reviewer this round (have registered already)',
'Not sure about the time/duties of the steering committee',
'but would be happy to know more about it',
'',
'Yes',
"I'd like to return as a mentor",
"I'd like to return as an expert",
'I am interesting in joining the OLS steering committee',
"I'd like to return as a collaborator to run this program in my network",
'No',
'I would not be able to return to OLS-8',
'I am on the last leg of my PhD so I dont have abandwidth to take up other commitments. While I woould like to remain a pat of the network ',
'I may join back as a mentor after my defence (probably after september.))',
"I've been thinking on a way to get the students on my community to participate on OLS regularly. Let's chat!",
'Happy to leave mentoring to other people',
'but can be a mentor in OLS-8 if needed',
'I would be happy to help out in anyway. There is wonderful overlap with the eLife Ambassadors community. Looking forward to discussing',
'I won’t have time :/ ']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(mentor_q3_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q3_df.plot.barh(ax=ax, colormap=colors['mentor_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
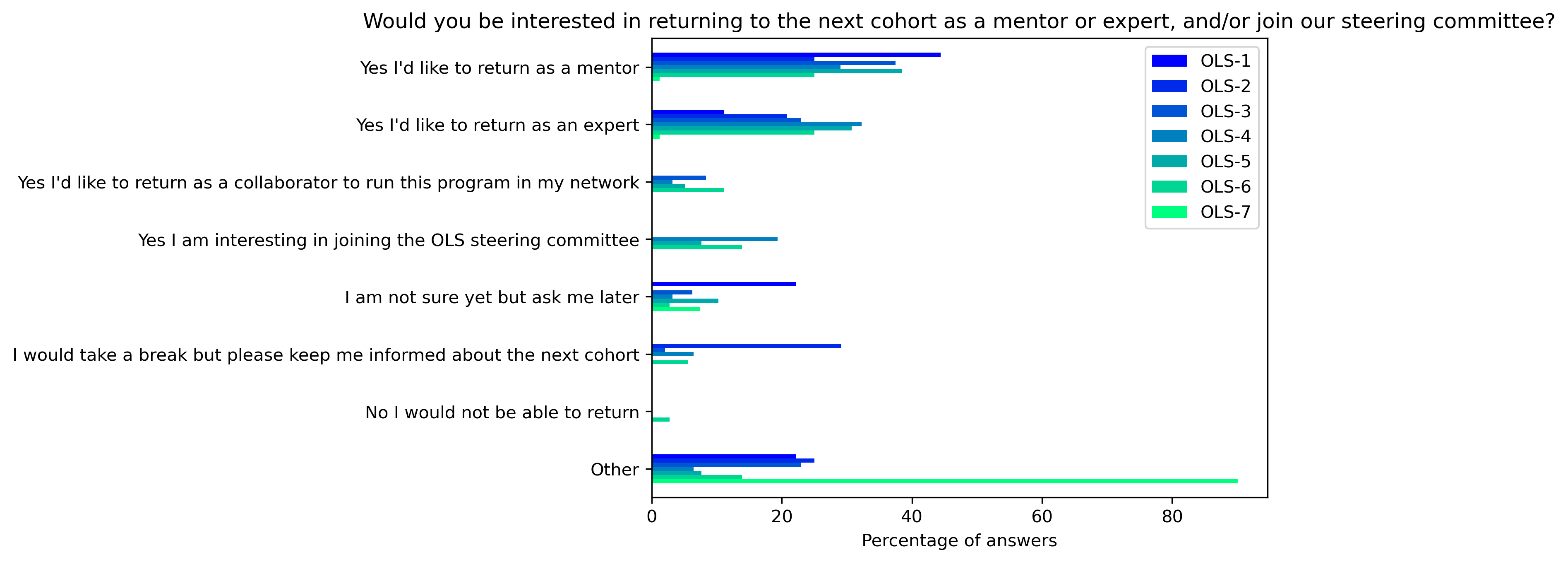
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q3_df.mean(axis=1).plot.barh(ax=ax, color=colors['mentors'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
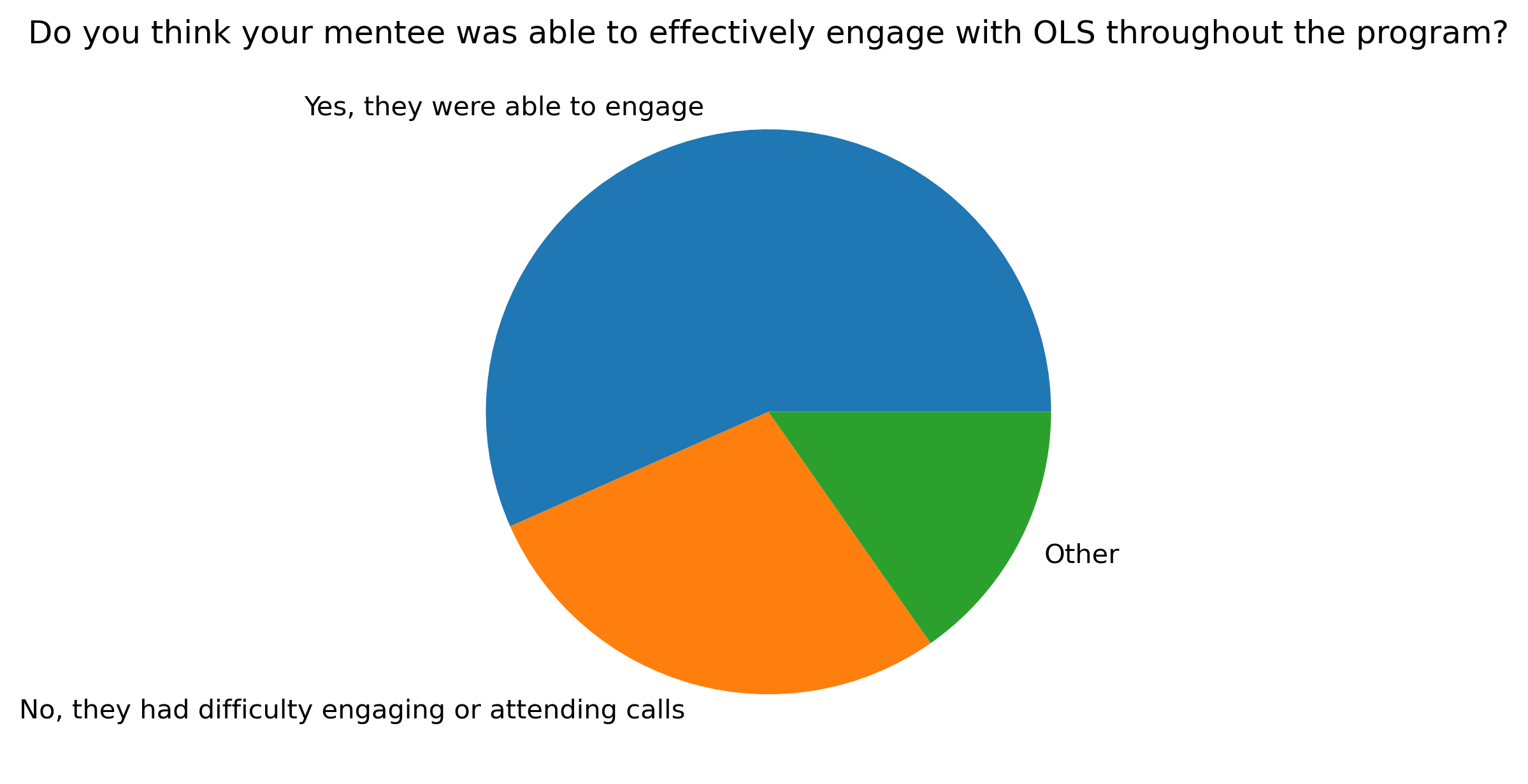
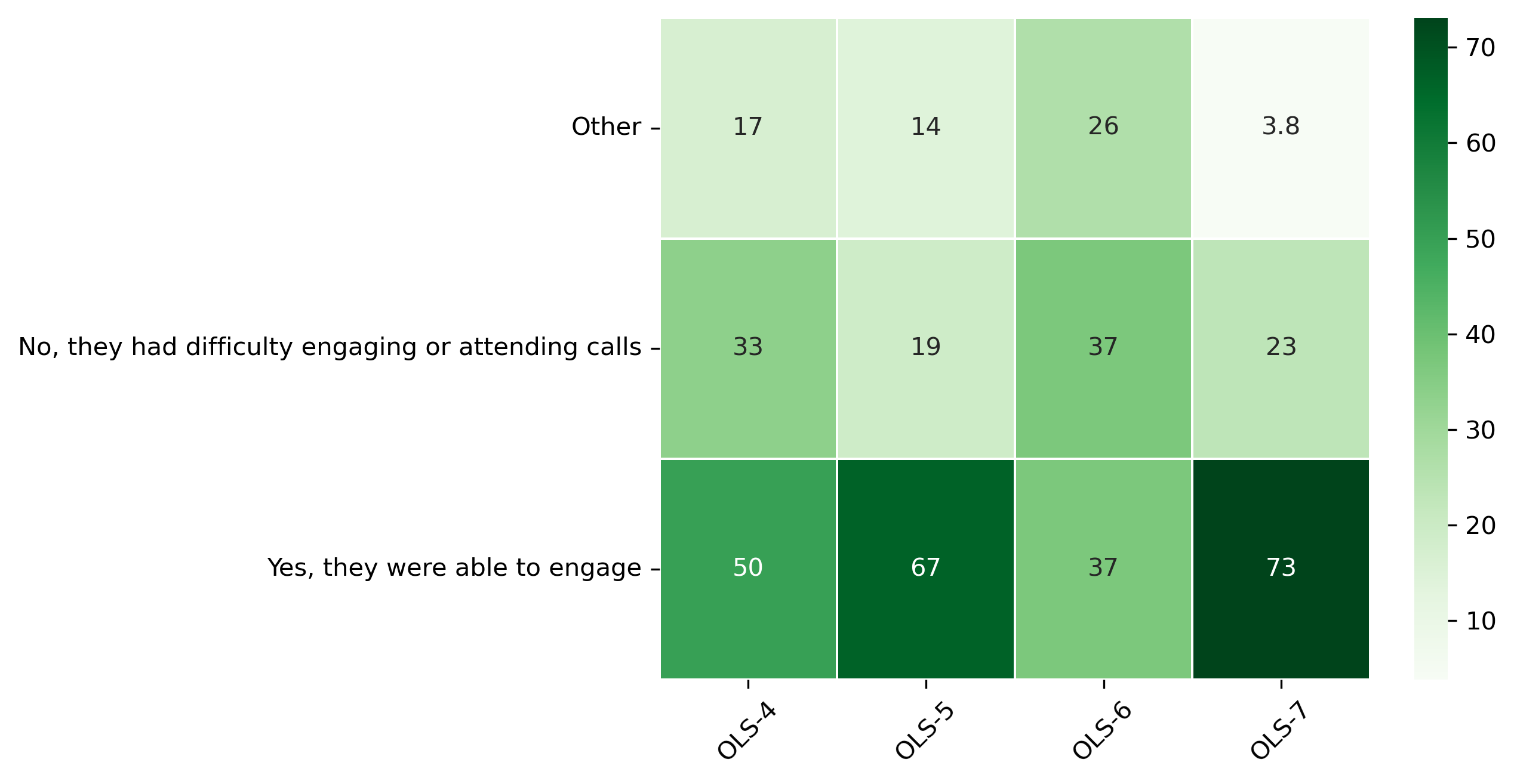
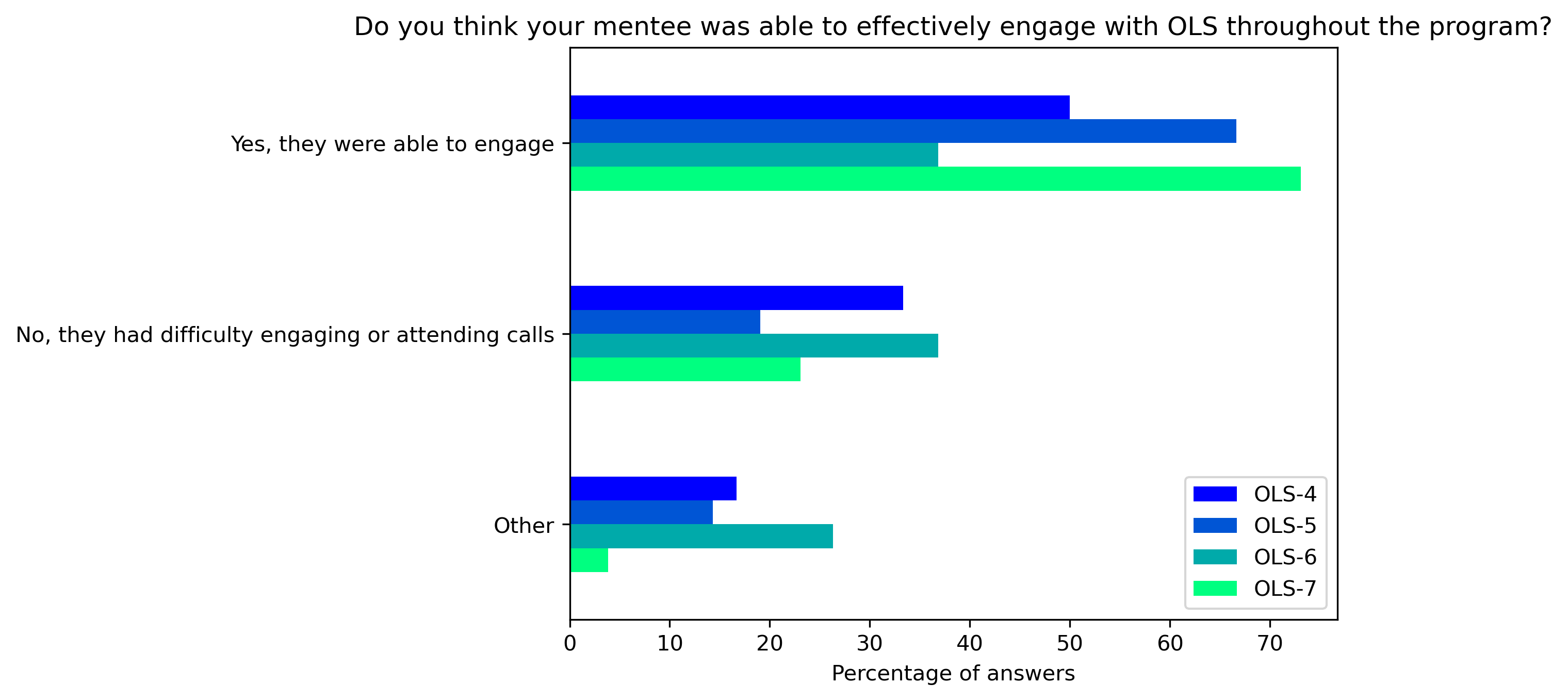
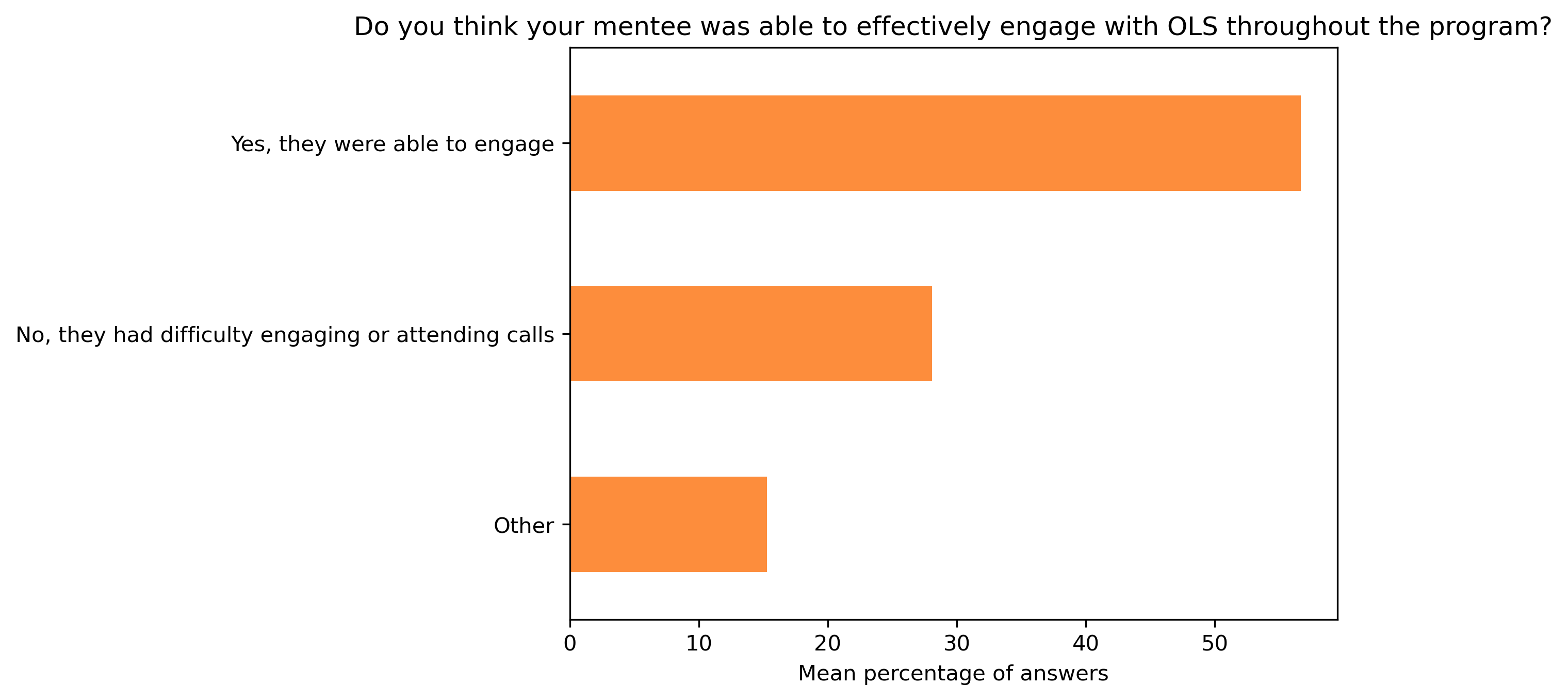
“Do you think your mentee was able to effectively engage with OLS throughout the program?”#
Possible answers:
Yes they were able to engage
No they had difficulty engaging or attending calls
Other
mentor_q4 = {}
other_answer = []
col = "Do you think your mentee was able to effectively engage with OLS throughout the program?"
answers = [
"Yes, they were able to engage",
"No, they had difficulty engaging or attending calls",
"Other"]
for c in mentor_df:
if col in mentor_df[c]:
mentor_q4[c], oa = get_question_possible_answers_counts(col, mentor_df[c], answers)
other_answer += oa
mentor_q4_df = pd.DataFrame.from_dict(mentor_q4)
mentor_q4_df = 100 * mentor_q4_df / mentor_q4_df.sum()
Other answers:
other_answer
['I think they were able to engage most of the time. They often had to catch up between the calls and what they effectively used in their project.',
"I think Arent was very much capable to effectively engage but I also received his feedback that he wished he had more time to really get the most out of it. I guess that's life :) Gill had a very busy time with teaching and the project changed focus in the middle of OLS so it was a bit more rough there. I think she managed to get at least something out of the programme but she has also been out of touch over christmas so I'm not sure if she's managing to graduate. I think in general people are just worn out over the pandemic: I myself was also not at my best in December and feel a bit more recharged right now. ",
'I think she was able to engage but did not attend a number of cohort calls, My guess (but take this as my hypothesis) is that thai partly related to being busy, and partly to the nature of the project, which involved organizing an event and thus some of the topics of the cohort calls would not have been applicable.',
"They were engaged with mentor calls, didn't manage to attend as many cohort calls as they wanted I think and probably also struggled with time to dig into all the material.",
'Perhaps not all members of the team but most of them',
'',
"I think Alden struggled in the beginning to keep up with all the homework, especially since her project wasn't actually funded yet so she was limited in what she could actually implement during the OLS program.",
'Did not manage to engage with Mahmood Usman, so not sure. ',
"she couldn't engage as much as she wanted",
'I think they were able to engage enough with the materials, a little less with th community per se becasue of language barriers',
'no, he had personal difficulty engaging or attending calls related to his VISA ',
'They had difficulty engaging with the mentorship side of the program but they were very active attending the community calls.']
fig, ax = plt.subplots()
fig.set_dpi(300)
sns.heatmap(mentor_q4_df[::-1], cmap='Greens', linewidths=0.5, annot=True)
plt.xticks(rotation=45)
plt.yticks(rotation='horizontal')
plt.show()
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q4_df.plot.barh(ax=ax, colormap=colors['mentor_colormap'])
plt.xlabel('Percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
#plt.savefig('../', bbox_inches='tight')
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q4_df.mean(axis=1).plot.barh(ax=ax, color=colors['mentors'])
plt.xlabel('Mean percentage of answers')
plt.gca().invert_yaxis()
t = plt.title(col)
fig, ax = plt.subplots()
fig.set_dpi(300)
mentor_q4_df.mean(axis=1).plot.pie()
t = plt.title(col)